In this Shane Hastie, Lead Editor for Culture & Methods, spoke to Phil Abernathy about his work helping organizations focus on employee happiness to drive customer happiness and shareholder return and the Bureaucracy Mass Index as a tool to identify where companies are bloated and ineffective. He also spoke about what’s needed for real transformation.
Great practical advice on building happier teams and a tool to measure bureaucracy in an organization.
Tony and Mark – supported by a global community of technologists, enthusiasts, and dreamers – brought 3D to the brand-new Web with VRML. This episode features Owen Rowley, Neil Redding, Linda Jacobson, Brian Behlendorf, John McCrea, Coco Conn — and Neal Stephenson.
With all the talk (and investment) in the metaverse, it is frustrating sometimes that people forget that the technology industry has been thinking and working on this for decades. Tony and Mark were instrumental in creating VRML, and I appreciate them documenting some of the history, but I was a bit disappointed that they omitted some of the other folks that were involved in the beginning.
Stated purpose: to unlock the potential of human creativity—by giving a million creative artists the opportunity to live off their art and billions of fans the opportunity to enjoy and be inspired by it.
Spotify is the most popular streaming service in the world, with 188 million people paying for premium subscriptions and hundreds of millions more listening for free on the ad supported tier. Which is why it has been called the world’s best place to get noticed as a musician. But getting noticed and making a living are two different things. In this episode we decide if Spotify is more about “Honesty” or “Little Lies?”. Listen in to find out.
One of our board members at Anaconda turned me onto this podcast. It’s about purpose-driven companies that don’t live up to their professed goals. This episode focuses on Spotify but also talks about the broader streaming music economy.
A16z Podcast – Creators, Creativity, and Technology with Bob Iger
A wide-ranging conversation with Bob Iger on the interplay between technology, content, and distribution; as well as Bob’s journey — and that of various creators! — especially as the industry evolved from TV and cable to the advent of the internet/ web 1.0 to 2.0 to briefly touching on web3 and other emerging technologies. As well as topics top of mind for all company and community builders: from build vs. buy and the innovator’s dilemma, to managing creativity, decentralization, remote work, and much more.
I didn’t expect to like this podcast as much as I did. I appreciated it not only for his takes on leading teams of creative people but also for his business acumen and for getting more details about creative people I admire and their work.
20VC – 20 Product: Marty Cagan on The Four Questions of Great Product Management, Product Lessons from Marc Andreessen, Ben Horowitz and eBay’s Pierre Omidyar & The Difference Between Truly Great Product Teams and the Rest
Marty Cagan is one of the OGs of Product and Product Management as the Founder of Silicon Valley Product Group. Before founding SVPG, Marty served as an executive responsible for defining and building products for some of the most successful companies in the world, including Hewlett-Packard, Netscape Communications, and eBay. He worked directly alongside Marc Andreesen and Ben Horowitz at Netscape and Pierre Omidyar at eBay.
I was not a fan of Cagan’s book Inspired. I called it “Ayn Rand for Product Managers.” I worked with some product managers who were all huge fans of it, and the result was not great for working with engineering.
In the time since, I have appreciated what Cagan said in his blog, which was a lot more focused on Lean-style product development and cross-functional collaborative teams. This podcast was further evidence for me that I need to re-evaluate how I see Cagan. I appreciated his perspective.
Planet Money – Episode 576: When Women Stopped Coding
Mark Zuckerberg. Bill Gates. Steve Jobs. Most of the big names in technology are men.
But a lot of computing pioneers, the ones who programmed the first digital computers, were women. And for decades, the number of women in computer science was growing.
But in 1984, something changed. The number of women in computer science flattened, and then plunged.
Today on the show, what was going on in 1984 that made so many women give up on computer science? We unravel a modern mystery in the U.S. labor force.
This podcast was oddly personal for me. It talks about how advertising and culture perpetuated a vision of computers as being for boys, discouraging women from entering the computing field. This was the time that I became fascinated by computers. I remember the ads, tv shows, and movies they discuss, and when I entered college for Computer Science my class was 70 men and 2 women. They also talk about my alma mater Carnegie Mellon and the steps that they have taken to address this imbalance.
It is amazing how quickly culture changed computing from being a female-dominated field to being a male one and then how long it has taken us to try and bring it back into some sort of equilibrium.
If you think you would like to use these ideas at your company, but you are unsure where to start, I can describe what we did at Avvo. I joined when the company was already nine years old. It had a mostly monolithic architecture running in a single data center with minimal redundancy.
There were some things that we did quickly to move to a more fail-safe world.
Moving from planning around objectives to planning around priorities
First, we worked to build a supportive culture that could handle the inevitable failures better. We moved from planning around specific deliverable commitments to organizing our work around priorities.
Suppose specific achievements, my output, measure my performance. This way of measuring performance often creates problems.
Suppose I need to coordinate with another person, and their commitments do not align to mine. That situation will create tension. If the company’s needs change, but my obligations do not, there is little incentive to reorient my work. To achieve my commitments, I can be thwarted by dependencies or hamper the priorities of the company.
People in leadership like quarterly goals or Managing By Objectives because they create strict accountability. If I commit to doing something and it is not complete when I say it will be, I have failed.
Suppose you think instead about aligning around priorities. In that case, those priorities may change from time to time. Still, if everyone is working against the same set of priorities, you can be sure that they are broadly doing the right things for the company. Aligning to priorities sets an expectation of outcome, not output.
Talk about failure with an eye to future improvement instead of blame
The senior leadership team must be aligned with these approaches. The rest of the organization may not be initially. When leaders talk about failure, they must do it with a learning message rather than blame or punishment. People should know that the expectation is that they may fail. If they are avoiding failure, then they probably aren’t thinking big enough. It is a message that “we want to see you fail, small, and we want to make sure we learn from that failure.”
I created our slack channel to share the lessons from our failures. I sent a message to my organization, making it clear that I don’t expect perfection. I shared my vision that we become a learning organization in town halls and one-on-ones.
Fail-safe architecture
Monoliths are natural when building a new company or when you have a small team. Monoliths are simple to make and more straightforward to deploy when you don’t have multiple teams building together. As the codebase and organization grow, microservices become a better model.
It is critical to recognize the point where a monolith is becoming a challenge instead of an enabler. Microservices require a lot more infrastructure to support them. The effort to transition from one architecture to another is significant, so it is best to prepare before the need becomes urgent.
Avvo had already started moving to a microservices architecture, but lack of investment stalled the transition. I increased investment in the infrastructure team. The team built tools that simplified the effort of creating, testing, monitoring, and deploying services. We then made rapid progress.
In every company, I use the lessons that I have shared in this article to build a culture where teams can innovate and learn from their users. It manifests differently with each group, but every team that has adopted these ideas has improved both business outcomes and employee satisfaction. Work with your peers to adopt some of these ideas. Start small and grow. The process of adopting these concepts mirrors the product development process you are working to build.
If you decide that it isn’t a good fit for your company, you will have failed smart by failing small.
I will leave you with a final thought from Henry Ford.
If you are a long-time Spotify user, you probably won’t recognize the interface shown in the photo below. In May of 2015, though, Spotify was very interested in telling the whole world about it. It was a new set of features in the product called “Spotify Now.”
I lead the engineering effort at Spotify on the Spotify Now set of features. It was the most extensive concerted effort that Spotify had done at the time, involving hundreds of employees across the world.
Spotify Now was a set of features built around bringing the right music for you at any moment in time. The perfect, personalized music for every user for every moment of the day. This effort included adding video, podcasts, the Running feature, a massive collection of new editorial and machine learning generated playlists, and a brand new, simplified user interface for accessing music. It was audacious for a reason. We knew that Apple would launch its Apple Music streaming product soon. We wanted to make a public statement that we were the most innovative platform. Our goal was to take the wind out of Apple’s sails (and sales!)
Given that this was Spotify and many of the things I’ve shared come from Spotify, we understood how to fail smart.
As we launched the project, I reviewed the project retrospective repository. I wanted to see what had and had not worked in large projects before. I was now prepared to make all new mistakes instead of repeating ones from the past.
We had a tight timeline, but some of the features were already in development. I felt confident. However, as we moved forward and the new features started to take shape in the product’s employee releases, there was a growing concern. We worried the new features weren’t going to be as compelling as the vision we had for them. We knew that we, as employees, were not the target users for the features. We were not representative of our users. To truly understand how the functionality would perform, we wanted to follow our product development methods and get the features in front of users to validate our hypotheses.
Publicly releasing the features to a narrow audience was a challenge at that time. The press, also aware of Apple’s impending launch, was watching every Spotify release exceptionally closely. They knew that we tested features, and they were looking for hints of what we would do to counter Apple.
Our marketing team wanted a big launch. This release was a statement, so we wanted a massive spike in Spotify’s coverage extolling our innovation. The press response would be muted if our features leaked in advance of the event.
There was pressure from marketing not to test the features and pressure from product engineering to follow our standard processes. Eventually, we found a compromise. We released early versions of the Spotify Now features to a relatively small cohort of New Zealand users. Satisfied that we were now testing these features in the market, we went back to building Spotify Now and preparing for the launch while waiting for the test results to come back.
After a few weeks, we got fantastic news. For our cohort, retention was 6% higher than the rest of our customer base.
For a subscription-based product like Spotify, customer retention is the most critical metric. It determines the Lifetime Value of the customer. The longer you stay using a subscription product, the more money the company will make from you.
With a company of the scale of Spotify, it was tough to move a core metric like retention significantly. A whole point move was rare and something to celebrate. With Spotify Now, we had a 6% increase! It was massive.
Now, all of our doubt was gone. We knew we were working on something exceptional. We’d validated it in the market! With real people!
On the launch day, Daniel Ek, Spotify’s CEO and founder, Gustav Söderstrom, the Chief Product Officer, and Rochelle King, the head of Spotify’s design organization, shared a stage in New York with famous musicians and television personalities. They walked through everything we had built. It was a lovely event. I shared a stage in the company’s headquarters in Stockholm with Shiva Rajaraman and Dan Sormaz, my product and design peers. We watched the event with our team, celebrating.
As soon as the event concluded, we started the rollout of the new features by releasing them to 1% of our customers in our four largest markets. We’d begun our Ship It phase! We drank champagne and ate prinsesstÃ¥rta.
I couldn’t wait to see how the features were doing in the market. After so much work, I wanted to start the progressive roll out to 100%. Daily, I would stop by the desk of the data scientist who was watching the numbers. For the first couple of days, he would send me away with a comment of “it is too early still. We’re not even close to statistical significance.” Then one day, instead, he said, “It is still too early to be sure, but we’re starting to see the trend take shape, and it doesn’t look like it will be as high as we’d hoped.” Every day after, his expression became dourer. Finally, it was official. Instead of the 6% increase we’d seen in testing, the new features produced a 1% decrease in retention. It was a seven-point difference between what we had tested and what we had launched.
Not only were our new features not enticing customers to stay longer on our platform, but we were driving them away! To say that this was a problem was an understatement. It was a colossal failure.
Now we had a big quandary. We had failed big instead of small. We had released several things together, so it was challenging to narrow down the problem. Additionally, we’d just had a major press event where we talked about all these features. There was coverage all over the internet. The world was now waiting for what we had promised, but we would lose customers if we rolled them out further.
Those results began one of the most challenging summers of our lives. We had to narrow down what was killing our retention in these new features. We started generating hypotheses and running tests within our cohort to find what had gone wrong.
The challenge was that the cohort was too small to run tests quickly (and it was shrinking every day as we lost customers). Eventually, we had to do the math to figure out how much money the company would lose if we expanded the cohort so our tests would run faster. The cost was determined to be justified, and so we grew the cohort to 5% of users in our top four markets.
Gradually, we figured out what in Spotify Now was causing users to quit the product. We removed those features and were able to roll out to the rest of the world with a more modest retention gain.
In the many retrospectives that followed to understand what mistakes we’d made (and what we had done correctly), we found failures in our perceptions of our customers, failures in our teams, and other areas.
It turns out that one of our biggest problems was a process failure. We had a bug in our A/B testing framework. That bug meant that we had accidentally rolled out our test to a cohort participating in a very different trial. A trial to establish a floor on what having no advertising in the free product would do for retention.
To Spotify’s immense credit, rather than punish me, my peers, and the team, instead, we were rewarded for how we handled the failure. The lessons we learned from the mistakes of Spotify Now were immensely beneficial to the company. Those lessons produced some of the company’s triumphs in the years that have followed, including Spotify’s most popular curated playlists, Discover Weekly, Release Radar, Daily Mixes, and podcasts.
How do we reduce the fuel-air bomb failure into an internal combustion failure? How can we fail safely?
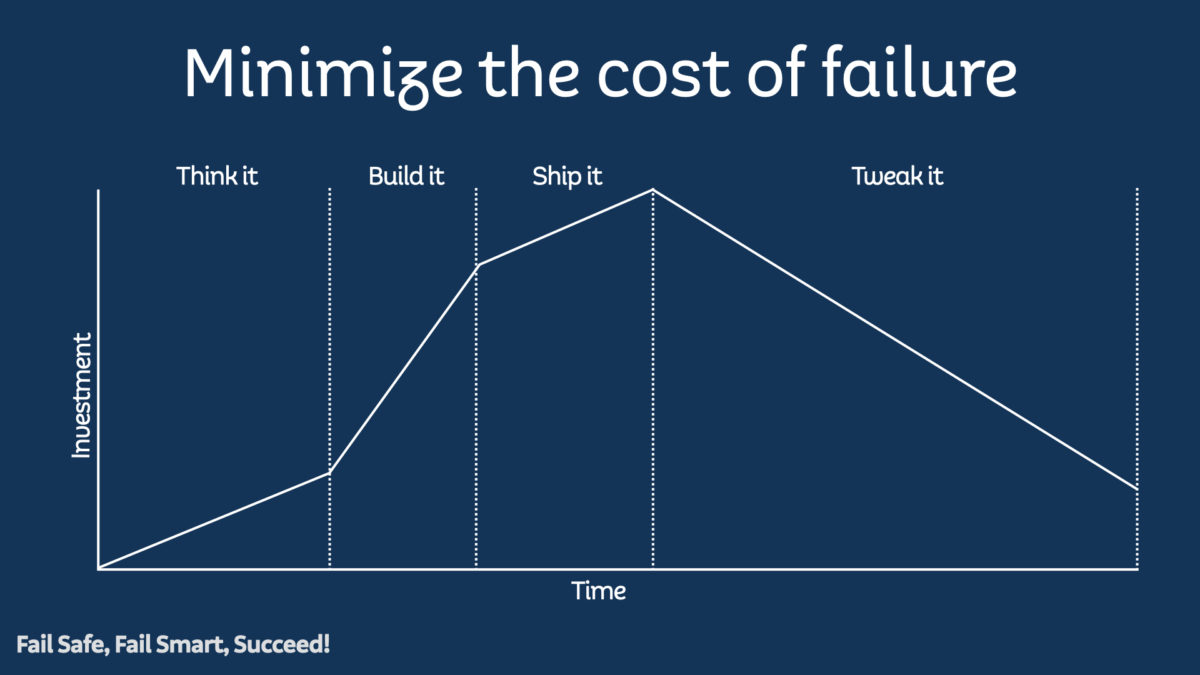
Minimizing the cost of failure
If you fail quickly, you are reducing the cost in time, equipment, and expenses. At Spotify, we had a framework, rooted in Lean Startup, that we used to reduce the cost of our failures. We named the framework “Think it, Build it, Ship it, Tweak it.“
This graph shows investment into a feature over time through the different phases of the framework. Investment here signifies people’s time, material costs, equipment, opportunity cost, whichever.
Think It
Imagine this scenario: you are coming back from lunch with some people you work with, and you have an idea for a new feature. You discuss it with your product owner, and they like the idea. You decide to explore if it would be a useful feature for the product. You have now entered the “Think It” phase. During this phase, you may work with the Product Owner and potentially a designer. This phase represents a part-time effort by a small subset of the team–a small investment.
You might create some paper prototypes to test out the idea with the team and with customers. You may develop some lightweight code prototypes. You may even ship a very early version of the feature to some users. The goal is to test as quickly and cheaply as possible and gather some real data on the feature’s viability.
You build a hypothesis on how the feature can positively impact the product, tied to real product metrics. This hypothesis is what you will validate against at each stage of the framework.
If the early data shows that the feature isn’t needed or wanted by customers, your hypothesis is incorrect. You have two choices. You may iterate and try a different permutation of the concept, staying in the Think It phase and keeping the investment low. You may decide that it wasn’t as good an idea as you hoped and end the effort before investing further.
If you decide to end during the Think It phase, congratulations! You’ve saved the company time and money building something that wasn’t necessary. Collect the lessons in a retrospective and share them so that everyone else can learn.
Build It
The initial tests look promising. The hypothesis isn’t validated, but the indicators warrant further investment. You have some direction from your tests for the first version of the feature.
Now is the time to build the feature for real. The investment increases substantially as the rest of the team gets involved.
How can you reduce the cost of failure in the Build It phase? You don’t build the fully realized conception of the feature. You develop the smallest version that will validate your initial hypothesis, the MVP. Your goal is validation with the broader customer set.
The Build It phase is where many companies I speak to get stuck. If you have the complete product vision in your head, finding the minimal representation seems like a weak concept. Folks in love with their ideas have a hard time finding the core element that validates the whole. Suppose the initial data that comes back for the MVP puts the hypothesis into question. In that case, it is easier to question the validity of the MVP than to examine the hypothesis’s validity. This issue of MVP is usually the most significant source of contention in the process.
It takes practice to figure out how to formulate a good MVP, but the effort is worth it. Imagine if the Clippy team had been able to ship an MVP. Better early feedback could have saved many person-years and millions of dollars. In my career, I have spent years (literally) building a product without shipping it. Our team’s leadership shifted product directions several times without ever validating or invalidating any of their hypotheses in the market. We learned nothing about the product opportunity, but the development team learned a lot about refactoring and building modular code.
Even during the Build It phase, there are opportunities to test the hypothesis: early internal releases, beta tests, user tests, and limited A/B tests can all be used to provide direction and information.
Ship It
Your MVP is ready to release to your customers! The validation with the limited release pools and the user testing shows that your hypothesis may be valid–time to ship.
In many, if not most, companies shipping a software release is still a binary thing. No users have it, and now all users have it. This approach robs you of an opportunity to fail cheaply! Your testing in Think It and Build It may have shown validation for your hypothesis. It may have also provided incorrect information, or you may have misinterpreted it. On the technical side, whatever you have done to this point will not have validated that your software performs correctly at scale.
Instead of shipping instantly to one hundred percent of your users, do a progressive rollout. At Spotify, we had the benefit of a fairly massive scale. This scale allowed us to ship to 1%, 5%, 10%, 25%, 50%, and then 99% of our users (we usually held back 1% of our users as a control group for some time). We could do this rollout relatively quickly while maintaining statistical significance due to our size.
If you have a smaller user base, you can still do this with fewer steps and get much of the value.
At each stage of the rollout, we’d use the product analytics to see if we were validating our assumptions. Remember that we always tied the hypothesis back to product metrics. We’d also watch our systems to make sure that they were handling the load appropriately and didn’t have any other technical issues or bugs arising.
If the analytics showed that we weren’t improving the product, we had two decisions again. Should we iterate and try different permutations of the idea, or should we stop and remove the feature?
Usually, if we reached this point, we would iterate, keeping to the same percentage of users. If this feature MVP wasn’t adding to the product, it took away from it, so rolling out further would be a bad idea. This rollout process was another way to reduce the cost of failure. It reduced the percentage of users seeing a change that may negatively affect product metrics. Sometimes, iterating and testing with a subset of users would give us the necessary direction to move forward with a better version of the MVP. Occasionally, we would realize that the hypothesis was invalid. We would then remove the feature (which is just as hard to do as you imagine, but it was more comfortable with the data validating the decision).
If we removed the feature during the Ship It phase, we would have wasted time and money. We still would have wasted a lot less than if we’d released a lousy feature to our entire customer base.
Tweak It
The shaded area under this graph shows the investment to get a feature to customers. You earn nothing against the investment until the feature’s release to all your customers. Until that point, you are just spending. The Think It/Ship It/Build It/Tweak It framework aims to reduce that shaded area; to reduce the amount of investment before you start seeing a return.
You have now released the MVP for the feature to all your customers. The product metrics validate the hypothesis that it is improving the product. You are now ready for the next and final phase, Tweak It.
The MVP does not realize the full product vision, and the metrics may be positive but not to the level of your hypothesis. There is a lot more opportunity here!
The result of the Ship It phase represents a new baseline for the product and the feature. The real-world usage data, customer support, reviews, forums, and user research can now inform your next steps.
The Tweak It phase represents a series of smaller Think It/Build It/Ship It/Tweak It efforts. From now, your team iteratively improves the shipped version of the feature and establishes new, better baselines. These efforts will involve less and less of the team over time, and the investment will decrease correspondingly.
When iterating, occasionally, you reach a local maximum. Your tweaks will result in smaller and smaller improvements to the product. Once again, you have two choices: move on to the next feature or look for another substantial opportunity with the current feature.
The difficulty is recognizing that there may be a much bigger opportunity nearby. When you reach this decision point, it can be beneficial to try a big experiment. You may also choose to take a step back and look for an opportunity that might be orthogonal to the original vision but could provide a significant improvement.
You notice in the graph that the investment never reaches zero. This gap reveals the secret, hidden, fifth step of the framework.
Maintain It
Even if there is no active development on a feature, it doesn’t mean that there isn’t any investment into it. The feature still takes up space in the product. It consumes valuable real estate in the UI. Its code makes adding other features harder. Library or system updates break it. Users find bugs. Writers have to maintain documentation about the functionality.
The investment cost means that it is critical not to add features to a product that do not demonstrably improve it. There is no such thing as a zero-cost feature. Suppose new functionality adds nothing to the product in terms of incremental value to users. In that case, the company must invest in maintaining it. Features that bring slight improvements to core metrics may not be worth preserving, given the additional complexity they add.
Expect failure all the time
When you talk about failure in the context of software development from the year 2000 to now, there is a substantial difference. Back then, you worked hard to write robust software, but the hardware was expected to be reasonably reliable. When there was a hardware failure, the software’s fault tolerance was of incidental importance. You didn’t want to cause errors yourself, but if the platform was unstable, there wasn’t much you were expected to do about it.
Today we live in a world with public clouds and mobile platforms where the environment is entirely beyond our control. AWS taught us a lot about how to handle failure in systems. This blog post from Netflix about their move to AWS was pivotal to the industry’s adapting to the new world.
Netflix’s approach to system design has been so beneficial to the industry. We assume that everything can be on fire all the time. You could write perfect software, and the scheduler is going to come and kill it on mobile. AWS will kill your process, and your service will be moved from one pod to another with no warning. We now write our software expecting failure to happen at any time.
We’ve learned that writing big systems makes handling failure complicated, so micro-service architectures have become more prevalent. Why? Because they are significantly more fault-tolerant, and when they fail, they fail small. Products like Amazon, Netflix, or Spotify all have large numbers of services running. A customer doesn’t notice if one or more instances of the services fail. When a service fails in those environments, the service is responsible for a small part of the experience; the other systems assume that it can fail. There are things like caching to compensate for a system disappearing.
Netflix has its famous chaos monkey testing, which randomly kills services or even entire availability zones. These tests make sure that their systems fail well.
Having an architecture composed of smaller services that are assumed to fail means that there is near zero user impact when there is a problem. Failing well is critical for these services and their user experience.
Smaller services also make it possible to use progressive rollout, feature flags, dark loading, blue-green deploys, and canary instances, making it easier to build in a fail-safe way.
If innovation requires failure, to build an innovative product or company, how your culture handles the inevitable failures is key to creating a fail-safe environment.
Many companies still punish projects or features that do not succeed. The same companies then wonder why their employees are so risk-averse. Punishing failure can take many forms, both obvious and subtle. Punishment can mean firing the team or leader who created an unsuccessful release or project. Sanctions are often more subtle:
Moving resources away from innovative efforts that don’t yield immediate successes.
Allowing people to ridicule failed efforts.
Continuing to invest in the slow, steady, growth projects instead of the more innovative but risky efforts. Innovator’s dilemma is just the most well-known aspect of this.
Breeding innovation out
I spend several years working at a company whose leadership was constantly extorting the employees to be more innovative and take more risks. It created ever-new processes to encourage new products to come from within the organization. It was also a company that had always grown through acquisition. Every year, it would acquire new companies. At the start of the next year’s budget process, there would inevitably be the realization that the company had now grown too large. Nearly every year, there would be a layoff.
If you are a senior leader and need to trim ten percent of your organization, where would you look? In previous years, you likely had already eliminated your lowest performers. Should you reduce the funding of the products that bring in your revenue or kill the new products that are struggling to make their first profit? The answer is clear if your bonus and salary are dependent on hitting revenue targets.
Through the culture of the company, it communicated that taking risks was detrimental to a career. So the company lost its most entrepreneurial employees either through voluntary or involuntary attrition. Because it could not innovate within, innovation could only happen through acquisitions, perpetuating the cycle.
If failure is punished, and failure is necessary for innovation, then punishing failure, either overtly or subtly, means that you are dis-incentivizing innovation.
Don’t punish failure. Punish not learning from failure. Punish failing big when you could have failed small first. Better yet, don’t punish at all. Reward the failures that produce essential lessons for the company and that the team handles well. Reward risk-taking if you want to encourage innovation.
Each failure allows you to learn many things. Take the time to learn those lessons
Learning from failure
It can be hard to learn the lessons from failure. When you fail, your instinct is to move on, to sweep it under the rug. You don’t want to wallow in your mistakes. However, if you move on too quickly, you miss the chance to gather all the lessons, which will lead to more failure instead of the success you’re seeking.
Lessons from failure: Your process
Sometimes the failure was in your process. The following exchange is fictional, but I’ve heard something very much like it more than once in my career.
“What happened with this release? Customers are complaining that it is incredibly buggy.”
“Well, the test team was working on a different project, so they jumped into this one late. We didn’t want to delay the release, so we cut the time for testing short and didn’t catch those issues. We had test automation, and it caught the issue, but there have been a lot of false positives, so no one was watching the results.”
“Did we do a beta test for this release? An employee release?”
“No.”
The above conversation indicates a problem with the software development process (and, for this specific example, a bit of a culture-of-quality problem). If you’ve ever had an exchange like the one above, what did you do to solve the underlying issues? If the answer is “not much,” you didn’t learn enough from the failure, and you likely had similar problems afterward.
Lessons from failure: your team
Sometimes your team is a significant factor in a failure. I don’t mean that the members of the group aren’t good at their jobs. Your team may be missing a skillset or have personality conflicts. Trust may be an issue within the team, and so people aren’t open with each other.
“The app is performing incredibly slowly. What is going on?”
“Well, we inherited this component that uses this data store, and no one on the team understands it. We’re learning it as we’re doing it, and it has become a performance problem.”
Suppose the above exchange happened in your team. In that case, you might make sure that the next time you decide to use (or inherit) a technology, you make sure that someone on the team knows it well, even if that means adding someone to the team.
Lessons from failure: your perception of your customers
A vein of failure, and a significant one in the lesson of Clippy, is having an incorrect mental model for your customer.
We all have myths about who our customers are. Why do I call them “myths”? The reason is that you can’t precisely read the minds of every one of your customers. At the beginning of a product’s life cycle, you may know each of your customers well when there are few of them. That condition, hopefully, will not last very long.
How do you build a model of your user? You do user research, talk to your customer service team, beta test, and read app reviews and tweets about your product. You read your product forums. You instrument your app and analyze user behavior.
We have many different ways of interacting with the subsets of our customers. Those interactions give us the feeling that we know what they want or who they are.
These interactions provide insights into your customers as an aggregate. They also fuel myths of who our customers are because they are a sampling of the whole. We can’t know all our customers, so we create personas in our minds or collectively for our team.
Suppose you have a great user research team, and you are very rigorous in your effort to understand your customers. You may be able to have in-depth knowledge about your users and their needs for your product. However, that knowledge and understanding will only be for a moment in time. Your product continues to evolve and change and hopefully add new users often. Your new customers come to your product because of the unique problems they can solve. Those problems are different from the existing users—your perception of your customers ages quickly. You are now building for who they were, not who they are.
Lessons from failure: your understanding of your product
You may think you understand your product; after all, you are the one who is building it! However, the product that your customers are using may be different from the product you are making.
You build your product to solve a problem. In your effort to solve that problem, you may also solve other problems for your customers that you didn’t anticipate. Your customers are delighted that they can solve this problem with your product. In their minds, this was a deliberate choice on your part.
Now you make a change that improves the original problem’s solution but breaks the unintended use case. Your customers are angry because you ruined their product!
Lessons from failure: yourself
Failure gives you a chance to learn more about yourself. Is there something you could do differently next time? Was there an external factor that is obvious in hindsight but could have been caught earlier if you approached things differently?
Our failures tend to be the hardest to dwell on. Our natural inclination is to find fault externally to console ourselves. It is worth taking some time to reflect on your performance. You will always find something that you can do that will help you the next time.
Collecting the lessons: Project Retrospectives
The best way that I have learned to extract the lessons is to do a project retrospective.
A project retrospective aims to understand what happened in the project from its inception to its conclusion. You are looking to understand each critical decision, what informed the decision, and its outcome.
In a project retrospective, you are looking for the things that went wrong, the things that went well, and the things that went well, but you could do better the next time. The output of the retrospective is neutral. It is not for establishing blame or awarding kudos. It exists to make sure you learn. For this reason, it is useful for both unsuccessful and highly successful projects.
A good practice for creating a great culture around failure is to make it the general custom to have a retrospective at the end of every project in your company. Having retrospectives only for the unsuccessful projects perpetuates a blame culture.
Since the project retrospectives are blameless, it is good to share them within your company. Create a project retrospective repository and publicize it.
The repository becomes a precious resource for everyone in your company. It shows what has worked and what has been challenging in your environment. It allows your teams to avoid making the mistakes of the past. We always want to be making new mistakes, not old ones!
The repository is also handy for new employees to teach them about how projects work in your company. Finally, it is also a resource for documenting product decisions.
The retrospective repository is a valuable place to capture the history of your products and your process.
Spotify’s failure-safe culture
I learned a lot about creating a failure safe culture when I worked at Spotify. Some of the great examples of this culture were:
One of the squads created a “Fail Wall” to capture the things they were learning. The squad didn’t hide the wall. It was on a whiteboard facing the hallway where everyone could see it.
This document is a report from one of the project retrospectives. You don’t need any special software for the record. For us, it was just a collection of Google docs in a shared folder.
One of the agile coaches created a slack channel for teams to share the lessons learned from failures with the whole company.
Spotify’s CTO posted an article encouraging everyone to celebrate the lessons that they learned from failure. Which inspired other posts like this:
If you look at the Spotify engineering blog, there are probably more posts about mistakes that we made than cool things we did in the years I worked there (2013-2016).
These kinds of posts are also valuable to the community. Often, when you are searching for something, it is because you are having a problem. We might have had the same issue. These posts are also very public expressions of the company culture.
Failure as a competitive advantage
We’re all going to fail. If my company can fail smart and fast, learning from our mistakes; while your company ignores the lessons from failure, my company will have a competitive advantage.
This article is about failure and everything I’ve learned from 28 years of failing (and succeeding) in the technology industry. Its basis is my talk of the same name that I first gave in 2015.
I’ve broken it into five parts to make it easier to read and share:
How we approach failure is critical in any industry, but it is especially crucial in building software.
Why?
The answer is simple: invention requires failure.
We don’t acknowledge that fact enough as an industry. Not broadly. It is something we should recognize and understand more. As technologists, we are continually looking for ways to transform existing businesses or build new products. We are an industry that grows on innovation and invention.
Real innovation is creating something uniquely new. If you can create something genuinely novel without failing a few times along the way, it probably isn’t very innovative. Albert Einstein expressed this as “Anyone who has never made a mistake has never tried anything new.”
In his own words, Thomas Edison says that he created three thousand different theories before he found the right materials for his electric light. To invent his battery, the laboratory performed over ten thousand experiments.
Filmmaker Kevin Smith says, “failure is success training.” I like that sentiment. It frames failure as leading to success.
Failure teaches you the things you need to know to succeed. Stated more strongly: failure is a requirement for success.
Creating a fail-safe environment
To achieve success, what’s important isn’t how to avoid failure; it’s how to handle failure when it comes. The handling of failure makes the difference between eventual success and never succeeding. Creating conditions conducive to learning from failure means creating a fail-safe environment.
In the software industry, we define a fail-safe environment as setting up processes to avoid failure. Instead, we should ensure that when the inevitable failure happens, we handle it well and reduce its impact. We want to fail smart.
When I was at Spotify, a company that worked hard to create a fail-smart environment, we described this as “minimizing the blast radius.” This quote from Mikael Krantz, the head architect at Spotify during that time, sums up the idea nicely: “we want to be an internal combustion engine, not a fuel-air bomb. Many small, controlled explosions, propelling us in a generally ok direction, not a huge blast leveling half the city.”
So, let us plan for failure. Let’s embrace the mistakes that are going to come in the smartest way possible. We can use those failures to move us forward and make sure that they are small enough not to take out the company. I like the combustion engine analogy because it embraces that failure, well-handled, pushes us in the right direction. If we anticipate, we can course correct and continue to move forward.
One way you can create these small, controlled explosions is to fail fast. Find the fastest, most straightforward path to learning. Can you validate your idea quickly? Can you reduce the concept down so that you can get it in front of real people immediately and get feedback before investing in a bunch of work? Failing fast is one of the critical elements of the Lean Startup methodology.
A side benefit of small failures is that they are easier to understand. You can identify what happened and learn from it. With a big failure, you must unpack and dig in to know where things went wrong.
I worked at Microsoft when the company created Office Assistant. Although I didn’t work on that team, I knew a few people who did.
It is easy to think that the Office Assistant was a horrible idea created by a group of poor-performing developers and product people, but that couldn’t be farther from the truth. Extremely talented developers, product leads, researchers with fantastic track records, and PhDs from top-tier universities built Clippy. People who thought they understood the market and their users. These world-class people were working on one of (if not THE) most successful software products of all-time at the apex of its popularity. Microsoft spent millions of dollars and multiple person-years on the development of Clippy.
So, what happened?
What happened is that those brilliant people were wrong. Very wrong, as all of us are from time to time. How could they have found their mistake before releasing widely? It wasn’t easy at the time to test product assumptions. It was much harder to validate hypotheses about users and their needs.
How we used to release software
Way back before we could assume high-bandwidth internet connections, we wrote and shipped software in a very different way.
Software products were manufactured, transcribed onto plastic and foil discs. For a release like Microsoft Office, those discs were manufactured in countries worldwide, put into boxes, then put onto trucks and trains and shipped to warehouses, like TV sets. From there, trucks would take them to stores where people would purchase them in person, take them home and spend an afternoon swapping the discs in and out of their computers, installing the software.
With a release like Office, Microsoft would need massive disc pressing capability. It required dozens of CD/DVD plants across the world to work simultaneously. That capability had to be booked years in advance. Microsoft would pay massive sums of money to take over the entire CD/DVD pressing industry essentially. This monopolization of disc manufacturing required a fixed duration. Moving or growing that window was monstrously expensive.
It was challenging to validate a new feature in that atmosphere, peculiarly if that feature was a significant part of a release that you didn’t want to leak to the press.
That was then; this is now.
Today, the world is very different. There is no excuse for not validating your ideas.
You can now deploy your website every time you hit save in your editor. You can ship your mobile app multiple times per week. You can try ideas almost as fast as you can think of them. You can try and fail and learn from the failure and make your product better continuously.
Thomas J Watson, the CEO of IBM from 1914 until 1956, said, “If you want to increase your success rate, double your failure rate.” If it takes you years and millions of dollars to fail and you want to double that, your company will not survive to see the eventual success. Failing Fast minimizes the impact of your failure by reducing the cost and delay in learning.
I worked at an IBM research lab a long time ago. I was a developer on a project building early versions of synchronized streaming media. After over a year of effort, we arranged to publish our work. As we prepared, we learned there were two other labs at IBM working on the same problems. We were done, it was too late to collaborate. At the time, it seemed to me like big-company stupidity, not realizing that three different teams were working on the same thing. Later I realized that this was a deliberate choice. It was how IBM failed fast. Since it took too long to fail serially, IBM had become good at failing in parallel.
I was inspired by this tweet from Dave Nicolette to talk a bit about what I look for when hiring Agile professionals.
Has anyone found that agile coaches are very good at describing an ideal end state, and less good at finding a path from present-day reality to that end state? Asking for a friend.
While I have been working exclusively with Agile techniques since we adopted Extreme Programming at a start-up where I was the development lead in 2000, I had never encountered a team-aligned full-time Agile professional before I joined Spotify in 2013. My prior experience with Agile was always that the team was responsible for it.
As a development lead, I was the XP coach when we did Extreme Programming. When my teams chose Scrum, I might take the role of Scrum Master, or it was the Program Manager, someone else on the team, or float between multiple people.
When I came to Spotify and found that I had three Agile coaches in my tribe, I was first a bit skeptical about the role. The coaches I worked with were not program managers, not scrum masters. They didn’t “lead” Agile in the teams with whom they worked. I wasn’t sure what their purpose was.
I first came to understand their value when one of them went on an extended vacation a few months after I started. At Spotify, I had found the most advanced and mature implementation of Agile/Lean product development at a scale that I have ever seen. I knew the coaches helped this, but I wasn’t sure how.
The coach went on their vacation, and everything kept going on as usual for a while. I would visit the stand-ups, and teams were adding stories and tracking them across the boards. One day I sat in on a squad’s stand-up and noticed that they had added a couple of swim lanes to their Kanban board. They now had more swim lanes than developers—a big red flag.
Over the weeks the coach was gone, the teams slowly slid into some bad habits. Velocity started to slip. I did my best to make them aware of this and get them back onto better paths, but I couldn’t be with each team enough.
The coach came back from vacation, and within a week or so, things were back to their high levels of performance. I wanted to see how he did it, and so I watched the ceremonies when I could. He didn’t cajole or quote Agile texts at them. He gently reminded them what good looked like, lessons they had learned in the past. He asked them many questions around why they thought what they were doing was a good idea. He didn’t “fix” them. He got them to fix themselves—a true coach.
Now I understood the value of the Agile coach role.
Good coach, bad coach
As Spotify grew and the number of Agile coaches in the company swelled, I also got to see some challenges with the role. Some coaches were highly effective and some less so. I had been lucky to start with three excellent coaches in my team. Some of my peers struggled with the coaches in their organizations.
As I came to understand the characteristics of the coaches that I found successful, I started to look for those qualities as we hired into our team. I have continued to look for those qualities as I have created those roles at companies in the US and UK where the role of Agile Coach (versus Scrum Master, Delivery Manager, or Agile Project Manager) is still novel.
Before I enumerate those characteristics, I want to make one point about careers as an Agile professional.
It is a tough job.
In many parts of the world, full-time Agile roles are very hard to come by. Mostly, companies hire Agile folks on a contractual basis. So, most Agile people have to string together six- or twelve-month stints at various companies trying to earn a living.
After reviewing hundreds of CVs in the US and Europe, the same companies show up often. These companies are always the ones who are in year X of a one-year Agile transformation program. Those are soul-crushing gigs.
The stringing together of short-term jobs can lead to a consultant mindset. These folks have the wisdom from having to jump into hostile environments, trying to survive. They have seen many mistakes that companies have made. Few have held the more extended roles where they have not only got teams functioning in an Agile way, but also helped them to evolve to a much better level. Their experience is broad, but not deep.
It is vital to keep that in mind as you review applicants, you need to understand their world and watch out for folks who have gotten stuck in that short-term mindset.
What I look for when I hire Agile coaches
A product development background. It isn’t critical which specific history the person has as a developer, tester, product manager, UX designer, engineering manager… I want to see that they had direct experience shipping a product. Agile roles have been around long enough that people can be trained in them in school and go right into the profession. From my experience, Agile people without experience building products can have a hard time making the trade-offs that are sometimes necessary. They may focus too much on the “how” without understanding the “why,” “what,” or “when.”
Broad knowledge of Agile frameworks and techniques. While the core of Agile thinking has been around for many years, new practices and methods continue to evolve. Like any profession, I look for a candidate to demonstrate that they are not only keeping up but are interested in what is happening in their field.
Experience growing a teams’ proficiency over time. As I mentioned above, many Agile professionals get stuck in an endless series of Agile transformations at different companies. While this is a valuable experience for an Agile consultant, it isn’t that practical for someone coming into a long-term role.
Pragmatic, not pedantic. Pragmatism is something I look for in everyone I hire. I would not expect this to be an issue for an Agile professional, but I have interviewed people whose definition of what was or was not correct was defined by a single book.
Knowing what good looks like. The characteristics of a high-performing Agile team are incredibly context-dependent. There is no single way to be an effectual team. So how do you convince teams to invest in improvement? You need to give them the vision of what they can be, which means that you need to know what “good” looks like.
Knowing what bad looks like. The converse of knowing what good looks like is knowing what bad looks like. I want to hear what the candidate identifies as harmful patterns in a team. The patterns they identify, help me understand how they look at teams. I also want to listen to their techniques for breaking teams out of these patterns. I want to hear what has worked and not worked for them.
A desire to build something bigger than themselves. I want to see some ambition in a coach. Not just to get a group working well, but to redefine what a group can achieve with the right support. If a candidate thinks their job is complete when the team has regular ceremonies, a groomed backlog, and a good flow of tickets, they probably aren’t what I am looking for.
Experience working with cross-functional stakeholders. Too many people view Agile as a software development thing, with defined boundaries aligned to the engineering team. Successful Agile organizations interface with the whole company, even if those functions do not choose to work in an Agile way.
Building an Agile coaching practice in your organization
If you want to build a new Agile coaching practice within your organization, it is best to start slow. Hire one coach, work with them to establish what the role means within your company. When the organization demands more time from them than they have to give, it will be time to hire a second coach, and so on.
Each coach should be able to support multiple teams, especially if you want the teams to own their practices instead of the coach (this is one reason why the coach should not be the scrum master for the groups they work with). Working with multiple groups also helps give some visibility across the organization about the quality of Agile practices and is an excellent conduit for best practice sharing.
You may have over-hired on coaches when the Agile coaches end up driving their deliverables and organizing their work as a function. That may mean that the coach to team ratio is off.
If you are serious about evolving your Agile practice as an organization and improving the quality, efficiency, and happiness of your teams, hire an Agile coach.
One of my family’s quarantine projects is re-assembling all my daughter’s old Lego sets. The pieces from the sets are in several large storage totes, mixed at random from years of building and taking things apart. As I was digging through a box today looking for some specific piece, I started noticing the system I had started to use.
As I looked for a piece, I would start to collect identical pieces and join them up. Joining pieces allows me later to find those pieces later more efficiently, even if I put them back into the box. It also reduced the number of pieces I would have to sort through to find anything. I do this unconsciously because I have done this ever since I was a kid.
Today I realized that this was a perfect metaphor for paying down technical debt.
Grouping the Legos as you are building means that you take a little bit longer on the sets you make at the beginning, but each successive set gets faster. Not only are there fewer Legos to sort through, but the Legos that are there are becoming more and more organized.
When working in a code base that has accumulated a lot of technical or architectural debt, cleaning things up as you go means that your velocity increases over time. Ignoring technical debt is like adding a few random Legos to the box as you take pieces out. Not only does it not get simpler or faster. It gets slower. Eventually, you have to go to the store to buy a new set because it is just easier than finding the pieces for the old one. Or worse, you have to go to eBay and pay twice as much for the same set because Lego stopped manufacturing it. (I am probably abusing the metaphor here.)
I’ve also been thinking about the difference between building a set by pulling out Legos from a big box versus building a brand-new set.
When you build a new set, the pieces come in smaller bags. Lego numbers the bags, so you only need to open one at a time to find the parts you need. Bigger sets may have multiple instruction books, also ordered by number.
The grouping of Lego pieces into bags is a metaphor for Agile software development.
By narrowing the scope and limiting the options, you make the work go faster, even when the problem is involved (like one of their expert models).
The next time you are trying to explain to your product manager (or anyone) why you need to add more tech-debt stories into the backlog even though it means a feature will take longer to deliver, bring in a big box of Legos as a teaching tool. If it doesn’t work, you’ll at least have a fun team meeting…
If your company is starting to plan for getting back into your office, now is a good time for you to schedule a personal strategy day.
The Whirlwind
In the whirlwind of the day-to-day work, it is often hard to carve out time for something that does not have a specific deliverable. Working from home can be even more challenging because of the additional pressures of helping your family. In the tech lead training program I am doing at Onfido, we are currently discussing how to be more strategic leaders. A familiar dictum of strategic thinking is the criticality of taking the time to think and plan.
The Personal Strategy Day
Liminal spaces are the transitionary spaces between things. In the liminal space between moving from working at home to being back fully in the office environment, you have an opportunity to try something new—a personal strategy day.
Block out a day in your calendar as people start moving back to the office. There will be some turbulence then as everyone is transitioning. It is the perfect time to start thinking about what you want to accomplish for yourself and your team before the whirlwind starts up again.
The Personal Off-site
Companies schedule off-sites to get away from the distractions of the office. If you can find a “third place” (a place that is not your office or your home) where you can focus, that is ideal. If not, book a secluded conference room in your office, or find an empty desk far from where you usually sit. If you are still at home, let your family know you are working, and need some blocks of focused time.
Focus
Don’t read your e-mail. Don’t take any meetings. Your job on that day is to think and plan. To help me focus, I will usually print out whatever supporting materials I think I need and work on paper to avoid the lure of notifications and other electronic distractions. Think of this as a gift of time and focus that you are giving yourself.
What to consider
Think of the time before the lockdowns began. You may have just been starting on your 2020 commitments and deliverables. What was going well then? What were your concerns? Now think through what you have learned about your team, the work, and yourself during the lockdown. What do you want to keep, and what do you want to discard as you go back to the office? What about the industry you are in, and the world at large has changed? What new pitfalls and opportunities are there? Now think ahead to the rest of the year. What new goals should you have for yourself and your team?
Take notes. Write things down. You will want to refer to them as you go through the year to revisit or remind yourself of your thinking.
Now make a plan. Not too detailed because the world is going to keep changing. Detailed enough that you feel as if you have something against which to execute. Write that down also. With milestones, if possible.
Finally, think about the process you just completed. Did it work for you? Would you do it again? If so, what would you change next time?
Retrospect and Revisit
This whole process may take anywhere from a couple of hours for you to an entire day. Don’t be too preoccupied with the length of time you spend. You are starting to build a practice of taking time for strategic thinking, so this is about taking more time than you have before.
If you found this valuable, you may want to plan your next strategy day for six or twelve months from now. Again, block it out in the calendar early and protect that time!
You may also find that it is good to schedule smaller blocks of time, weekly or monthly, to revisit your plan, track progress, and make adjustments. These blocks of time are strategic thinking too!
Conclusion
If you struggle to keep time for strategy, building a structured approach like a personal strategy day may help you create a practice. Using the liminal times like transitioning from lockdown back to whatever it is that comes after is an opportunity to block and protect time. The liminal times are also crucial for strategy because your past assumptions are likely no longer correct, and there may be some opportunities or challenges that weren’t visible before.
Some resources
I’ve spent the last several years building a structured personal strategy process for myself. Many people have inspired my practice. Their suggestions may inspire you as well.
The planners from the Ink+Volt team helped me build some structure around my strategy, and also regular time to revisit and update it. Kate Matsudaira (who is also a very established technology leader) provides useful structured planning and strategic thinking documents in her newsletter and on their blog. https://inkandvolt.com/blogs/articles
In Pat Kua’s LevelUp newsletter, the issues near the end and the start of the year included many planning and strategy resources. http://levelup.patkua.com/#archive