What tech debt actually tells you about your team and your system
Miami Beach, USA – Photo by Kevin Goldsmith – December 2025
Tech debt comes up constantly: in mentoring conversations, consulting work, conference Q&A, and inside my own teams. I’m always a little surprised by how often it’s treated as a moral failure rather than what it usually is: a set of trade-offs made under real constraints.
That framing matters because tech debt isn’t inherently good or bad. It’s a consequence of shipping. If you’re delivering real value, especially in an environment that values learning and iteration, you’re accumulating debt all the time. Every line of code you ship today is tomorrow’s constraint.
The question isn’t whether you have tech debt. The question is whether you understand why it exists and what it’s doing to your system.
Early in my career, I thought tech debt meant someone made a bad decision. Experience taught me otherwise. Some debt is deliberate. Some is benign. Some is dangerous. And some isn’t really about code at all, it’s a signal that something upstream is broken.
Tech debt as a leadership problem
The real leadership tension around tech debt is that it all looks the same in a backlog. Engineering feels the pain and wants to fix it. Product wants to hit dates. Executives want predictable results. From the outside, “we need to spend three sprints on tech debt” just sounds like unpredictability.
I’ve lived this from both sides. Early in my career, after inheriting a large, aging codebase that was genuinely holding a company back, I swung too far in the other direction at my next startup. Determined not to repeat that experience, I over-architected for a future we hadn’t earned yet. We built systems for a five?year horizon when we were still trying to survive the next six months.
Eventually, reality caught up with us. The complexity slowed us down more than the hypothetical debt ever would have. The lesson stuck: avoiding tech debt at all costs can be just as damaging as ignoring it entirely. Both mistakes stem from treating tech debt as a moral rather than a contextual issue.
That tension exists because tech debt covers very different underlying realities. Deliberate shortcuts, accidental architectural drift, aging technology choices, and systemic organizational issues all surface the same way: as work engineers would like to do.
If you don’t distinguish between those causes, you’ll either fix the wrong things or fail to fix what actually matters.
Four kinds of tech debt
Over time, I’ve found it useful to think about tech debt through four lenses, based on intent and impact. This framing isn’t a framework so much as a way to avoid treating very different problems as if they were the same.
Pragmatic (intentional) debt. This is debt you take on by choice: because you’re validating an idea, avoiding premature optimization, or buying time to learn. Healthy teams do this constantly. It’s a sign of good judgment, not sloppiness. The failure mode here isn’t taking on the debt; it’s taking it on invisibly or failing to revisit the decision.
A helpful test is simple: did we understand the trade-off when we made it?
Required debt. This is debt that actively constrains the business: reliability issues, security risks, scalability limits, or architectural bottlenecks that slow delivery. This debt isn’t optional. Avoiding it just increases the eventual cost.
The key question here isn’t “does this bother engineers?” It’s “does this prevent the business from moving in a strategic direction?” If the answer is yes, and you can measure it, you have required work.
Incidental debt. Every mature codebase has code that isn’t pretty, isn’t modern, and isn’t fun to work on, but works reliably and is rarely touched. This debt is usually safe to ignore.
Refactoring something simply because you don’t like it is frustration, not strategy. The cost of touching stable code is often higher than the cost of living with it.
The question to ask is: is fixing this cheaper than leaving it alone?
Symptomatic debt. This is the most dangerous kind. It’s debt that keeps reappearing because of unclear strategy, constant priority shifts, fractured ownership, or organizations that leave no capacity for anything but delivery.
Fixing the code doesn’t fix the problem. The system that produced the debt will just generate more of it somewhere else.
Here, the real question is: what system is creating this debt?
Why teams get stuck
Most teams struggle because they treat all tech debt as equally urgent or equally ignorable. Neither is true. Only one of these categories demands immediate action. The rest require judgment, patience, or leadership intervention outside the codebase.
I’ve seen this play out repeatedly. A monolith that was absolutely the right choice for a small team slowly becomes a deployment bottleneck as the organization grows. What was once enabling starts constraining. The mistake isn’t the original decision—it’s failing to recognize when the context changed.
I’ve also seen the opposite: teams over-architecting far into the future, building complexity they don’t yet need, because they’re trying to avoid hypothetical debt five years out while ignoring the real problem six months away.
Both mistakes come from the same place: losing sight of intent.
Making better tech debt decisions
Treat tech debt decisions like any other strategic trade-off. They deserve the same level of judgment, visibility, and follow-through as product or organizational decisions. Make them deliberate, visible, and tied to business outcomes.
If you want support from product partners, executives, or peers, you must speak the language of impact. Reliability, cycle time, risk, and optionality are business concerns, not engineering preferences.
A few practical heuristics help:
Track intentional debt and revisit it deliberately.
Prioritize required debt alongside roadmap work, not as an afterthought.
Leave incidental debt alone unless it becomes chronic.
For symptomatic debt, stop coding and start examining structure, incentives, and capacity.
Mapping how work actually flows through your organization is often more revealing than reviewing the code. Consistent friction points usually point to systemic issues, not isolated mistakes.
The human layer
Most tech debt isn’t about code. It’s about pressure.
Engineers feel guilty about shortcuts unless leaders normalize intentional debt as a legitimate tool. Product partners need clarity that some debt is an investment in learning faster. Executives need visibility into which debt threatens outcomes and which doesn’t.
When leaders promise to revisit a debt decision, they have to follow through, even if the answer is still “we’re leaving it.” Broken promises push teams toward overbuilding today because they don’t trust tomorrow.
Teams under constant delivery pressure don’t accumulate debt because they lack skill. They do it because the system leaves them no alternative. Left unaddressed, that pressure undermines morale and code quality.
How to apply this tomorrow
You don’t need a multi?quarter initiative to start improving how your team handles tech debt. A few small, deliberate moves can immediately change the conversation.
Start by identifying the top three sources of recurring pain your team complains about. Not everything, just the things that keep coming up sprint after sprint. Categorize each one honestly: pragmatic, required, incidental, or symptomatic. The act of naming the type often clarifies the decision.
For any intentional debt, write down why you chose it, what problem it solved, and when you’ll revisit it. Put a reminder on the calendar. If you say you’ll come back in six months, actually do it.
For debt that feels urgent, force a business?impact discussion. What does this slow down? What risk does it introduce today, not someday? If you can’t connect it to outcomes, it probably isn’t required yet.
And if you see the same kinds of problems appearing across multiple areas of the system, pause before opening another refactoring ticket. Ask what incentives, structures, or capacity constraints are creating that pattern. That’s a leadership problem, not a coding task.
These steps won’t eliminate tech debt. They will make it legible. And once tech debt is legible, it becomes manageable.
Tech debt as a diagnostic
There’s a line I come back to often when thinking about this:
Tech debt is code telling you a people story.
The shape of your codebase reflects the incentives, constraints, and trade-offs your teams live with every day. Some debt exists because you chose speed over elegance. Some exists because the business changed direction. Some exists because no one ever had the space to step back and ask if the system still made sense.
Seen this way, tech debt becomes less about cleanliness and more about comprehension. It tells you where judgment was exercised well, where context shifted, and where leadership attention is overdue.
These days, I look at tech debt less as a technical flaw and more as a diagnostic signal. How much of it was intentional? How much is benign? How much is actively constraining outcomes? And how much is a warning that the organizational system, not the software system, needs work?
Start with intent. Then look at the system. Only then decide what to fix.
Reading the Signal
Tech debt isn’t inherently good or bad. It’s information.
If you treat every piece of debt as a defect, you’ll waste time and erode trust. If you treat every piece as harmless, you’ll create fragility that eventually surfaces at the worst possible moment. The leverage comes from understanding why the debt exists and what it reveals about your team and your organization.
When you slow down enough to interpret the signal, rather than react to the symptom, you make better decisions for your team, your product, and your company.
Every few years, a new wave of technology arrives, and people in our industry start to declare that everything is about to change. Right now, that wave is generative AI. A few years ago, it was Web3. Before that, mobile and public cloud. Before those, the web itself. Some of these shifts turned out to be genuinely transformative. Others didn’t.
Having lived through enough of these cycles, I have learned that the excitement and fear are always the same. The hard part is never knowing in the moment which changes will last. The other hard part is that, as technology leaders, we have to make decisions about them anyway. Should we adopt this new thing? Wait it out? Ignore it? Every one of those choices comes with a cost.
AI is the current case study, but the real question is broader. How do we make technology choices at all? How do we separate what is genuinely important from what is just noise?
Curiosity with Discipline
Being a technical leader involves staying curious. You have to pay attention to what is happening in the industry. That means reading, listening, and talking to peers. You cannot afford to ignore change because sometimes it is not a fad at all. Sometimes it is the thing that allows the next generation of companies to surpass your company.
Hopefully, you don’t see this curiosity as a burden. You chose a career in technology, after all!
But curiosity alone is not enough. There has to be discipline behind it. I have seen teams that refactor constantly, switching frameworks every few months or adopting tools that promise faster builds or cleaner syntax. They expend a great deal of energy and end up standing in the same place. It is easy to confuse motion with progress.
The goal is not to be early. The goal is to be ready when it matters.
Knowing When to Pay Attention
When something new appears, the first question is not “should we use it,” but “should we even pay attention to it?” Most technologies take a while to prove themselves. They start with hobbyists and early adopters. Then you begin to hear about them in conference talks and blog posts. If you start to see teams you respect using it, that is a signal to look more closely.
There are exceptions. Sometimes, a new tool or framework solves a problem that nothing else does. If it unlocks something meaningful for your business or team, consider taking the risk of early adoption. But most of the time, patience pays off. You want to see that a technology has a community around it, good documentation, and some stability. You want to know that if the creator moves on, the thing won’t go away.
I have seen open-source projects from large companies become popular overnight, only to discover that they were designed to address those companies’ unique constraints. They required more effort to maintain than smaller teams could afford. The code was free, but there was a hidden cost in maintenance. Before adopting the new tool, ensure you are familiar with its operation and can use it efficiently.
Use the Curiosity Around You
You don’t have to do all the exploration yourself. The best engineering teams already have people who watch the industry and bring new ideas. You can turn that energy into a system.
Give people permission to explore. Encourage them to read, share, and experiment safely. Create a channel or regular forum where developers can showcase their work, whether it is a side project or a prototype. It shows them that curiosity is valued, not something to hide until after work hours.
You can tell a lot about your team’s culture by how it reacts to experimentation. If people are afraid to try things, they stop learning. If you reward them for exploring ideas responsibly, you build a team that continues to grow even when the company is stable.
Let the eager ones go first, but set boundaries. They should know what kinds of experiments are helpful in the business. Guide their curiosity. The best developers don’t need permission to learn, but they do appreciate direction.
Evaluating What You Find
When something looks promising, that is when leadership really matters. You have to evaluate it in a way that balances technical interest with business sense.
Start with questions:
What problem does this solve for us right now?
Is it mature enough for the scale and reliability we need?
What are the maintenance implications?
Who else is using it successfully, and what can we learn from them?
Build a small proof of concept. Keep it outside production at first. Compare it with what you already have. Measure performance, stability, and effort. Run it in parallel with your current solution so you can see real data before committing (shadow testing).
This part takes patience. It is easy to fall in love with a clean new abstraction or a faster benchmark. But the actual cost of new technology is rarely visible at the start. The hardest lesson I have learned is that the adoption work is always more expensive than it looks. The second-hardest is that we almost always underestimate the maintenance cost.
If possible, discuss with peers at similar companies. Ask them what happened when they tried it. Did it actually deliver value? Did it hold up? You can save months of effort just by learning from other teams’ experiments.
Managing the People Side
Every new technology comes with human change as well. Some team members will be excited. Others will resist it. Both reactions are normal.
The eager developers will show up ready to rebuild everything in the new tool. The skeptics will say there’s no need to change what already works. Both have a point.
Your job is to balance them. Channel the energy of the early adopters toward solving real problems. Give them structure and goals. At the same time, acknowledge the fear of the skeptics. For many engineers, expertise is tied to identity. When you replace a system they know deeply, it can feel like erasing years of experience.
Pair the enthusiasts with the skeptics. Let them learn from each other. Measure the results and share them openly. When the experiment works, celebrate the outcome. When it doesn’t, celebrate the learning. What matters is not whether every experiment succeeds, but whether the organization learns at a faster rate.
You cannot let your early adopters run wild, but you also cannot let the cautious ones stop progress. Most of the time, the right path sits somewhere between.
How to Adopt Deliberately
When you decide to move forward with something new, make it an experiment, not a crusade. Define a hypothesis about what you expect to gain. You may be looking for better scalability, lower costs, or a faster development cycle. Write that down. Then define how you will measure it.
Expect the transition to follow a change curve. Things will feel worse before they get better. People will struggle with the new approach and question why you made the switch. That is normal. Keep communicating what you are seeing and why you are continuing. When the metrics begin to show improvement, make that visible.
If it doesn’t deliver the results you hoped for, be willing to stop. End the experiment, share what you learned, and move on. That kind of clarity builds trust.
When it does work, document it. Recognize the people who led the effort. Build on that experience the next time. Adoption is not just a technical process. It is a cultural one.
Building a System for Technology Choices
The most successful organizations I have worked in treat technology decisions as part of their system, not a one-time event. They create space for discovery, experimentation, and evaluation before anything reaches production. They involve the team in technical direction, not just management.
If you are a CTO, you own the technology strategy; however, the best strategies often emerge from shared ownership. The people doing the work often see opportunities or risks before you do. Involve them. Encourage them to propose ideas, test them safely, and share what they learn.
After every adoption or rejection, hold a retrospective. Talk about what worked, what didn’t, and what to do differently next time. That habit turns random trial and error into institutional learning.
You can build a culture that views new technology not as a threat or distraction, but as an integral part of how the team evolves. Curiosity and discernment can coexist.
Closing Thought
Technology waves will keep coming. Some will reshape how we work; most will not. The challenge of leadership is recognizing the difference.
Good technology choices rarely come from being first. They stem from being thoughtful, from understanding your context, and from fostering a culture that learns quickly and acts deliberately.
The best technology decisions are not about what is new. They are about what is right for you, right now.
In the last post, I shared the books that I found worth recommending that I read in 2022. The next post shares podcasts that I found valuable. In this (longer) post, I will share links to the blog posts from 2022 that I think are recommendation worthy. I’ve broken it into sections based on content.
As a CTO, I spend a lot of my time thinking about building effective technology organizations, and I’m always looking for new approaches or lessons in the space.
The pandemic has caused nearly two years of collective trauma. Many people are near a breaking point.
An airplane passenger is accused of attacking a flight attendant and breaking bones in her face. Three New York City tourists assaulted a restaurant host who…
If you are wondering why people are such jerks now…
Learn about the How HashiCorp Works project and why there are links to internal HashiCorp materials in this article. Our…
I like the movement in making how companies work transparent. It is useful to read as a leader and a great recruiting tool for those companies. I always wonder how much reality matches the shared documents. If you know you will share with the public, you are likely to be a bit more aspirational than actual, but it is still useful to read.
Medium sees more employee exits after CEO publishes ‘culture memo’ – TechCrunch
The sign that Netflix’s culture had irreversibly started to…
The genius of Netflix as an employer was that it has always been very upfront about who it is and how it works, with the understanding that anyone taking a job there knows what they are getting into. This works great until the culture starts to change, so this isn’t about an individual employee being unhappy. It will be interesting to see how Netflix navigates this (or doesn’t).
Culture as a Product: How HubSpot Built its Famed Startup Culture
Around Boston and beyond, HubSpot is known for its strong entrepreneurial culture . The company has received many awards over the years and was recently named…
Hubspot is an interesting company. Having read Disrupted (https://www.amazon.com/Disrupted-Dan-Lyons/dp/0316306096) I am a bit skeptical of how they talk about themselves, but of course, one always should be. That said, even if the public face of companies’ cultures is more aspirational than real, there is still something to be learned. I didn’t decide that the 37 Signals books were worthless because when under stress, the company didn’t live the values they proclaimed.
Bolt Loaned Employees Thousands to Buy Stock—Then Laid Them Off
The challenge of startup options is that employees rarely are allowed to sell them. When a startup has been around a long time, and startup options are starting to expire, but employees have had the liquidity event necessary to have ready cash to exercise their options, what are they to do? A company I was in also considered a loan program for employees but decided it was potentially problematic. Bolt learned that lesson the hard way, and their former employees are worse off for it.
A big 32-hour workweek test is underway. Supporters think it could help productivity
This article was originally written for LeadDev . In tech, we talk a lot about failing fast: implementing small, incremental…
I talk a lot about failure, failing fast, etc… This article is an actual case study in how to recover when your team has a big failure. I always like real-life stories instead of vague opinion pieces.
Career Development: What It Really Means to be a Manager, Director, or VP
It’s no secret that I’m not a fan of big-company HR practices. I’m more of the First Break all the Rules type. Despite my general skepticism of many standard…
There are tons of posts and books about being a line manager. There are substantially less about levels beyond that. I’m always looking for informative articles or books about more senior leadership levels. This was a decent one.
There is a euphemism in rocketry often heard at SpaceX – Rapid Unscheduled Disassembly. A catastrophic explosion, in other words. Until now, it was not…
The speed of Elon’s decline from “genius who can see a better future and bring it about” to “asshole snake oil salesman with a narcissistic personality disorder” was sudden by any measure. How do we keep people like this from ruining our favorite apps/sites? By keeping ownership and infrastructure distributed…
Remote Work/Return to the office
For the last couple of years, the push and pull of remote vs hybrid vs back-in-the-office has been a major story in the work press. I’ve already made my decision that I’m going to keep working remote and will choose companies that allow me to do that, but in all of this discussion I’m also looking to understand how other companies are approaching things.
Why workers are calling BS on leaders about returning to the office
This may be losing some of its value as it ages, but speaking as an all-remote company CTO, if you don’t listen to your employees about how they want to work, I’ll be happy to take them off your hands.
The Future of Work Isn’t Fancy Tech. It’s Remote Work and Smarter Management
The remote/office debate is dying down any time soon. There is more pressure on returning to offices now, but there is also more resistance. Given the layoffs, employees may not feel empowered to resist the call to return to the office, so maybe that will gain ground.
The Worst Part of Working From Home Is Now Haunting Reopened Offices
Few people are as knee-deep in our work-related anxieties and sticky office politics…
If a primary driver for bringing people back to the office is better collaboration, you may want to consider how your hybrid remote/office system is set up.
How to embrace asynchronous communication for remote work
How to get started with async GitLab believes that…
The secret to successful remote work (especially if the team is spread across time zones) is moving to be asynchronous first. The companies that have been distributed for long periods and have scaled have embraced this, but it is harder than it seems, and many companies struggle. Even those that have always been distributed. This GitLab guide is very helpful.
Web Technologies
I spent much of 2022 learning more about WebAssembly as we launched PyScript at Anaconda. I think that it has some amazing potential and is one of the most important technologies of the last few years.
This article explains the concepts behind how WebAssembly works including its goals, the problems it solves, and how it runs inside the web…
If you are in technology, you need to understand WebAssembly and how it can be used. It can potentially be more transformative than many of the technologies we depend on for software development today.
A short history of Flash & the forgotten Flash Website movement (when websites were “the new emerging artform”)
This post is a transcript of a talk I gave at UCSC. Thank you for inviting me! I’m sharing it here because It’s a GOOD summary of the history of a technology…
If you were active on the web in the 90s and early 2000s, you will remember the explosion of massively creative web experiences propelled by the Macromedia/Adobe technology Flash. While you can still create those kinds of experiences using modern web technologies, it now requires a level of coding expertise that puts the programmers in the driver’s seat instead of the artist/designer and requires a team instead of a single creative person.
The genius of Flash was that it made complex interactivity and visuals easy for many artists to create, and the result was beautiful chaos. The web is just a bit more boring for the death of Flash.
Spotify’s grand plan to monetize its open source Backstage project via premium plugins
Backstage was created when I was at Spotify. Even in its earliest days, it solved many problems for us in a massively micro-service architecture. It’s cool to see how it has developed over the years, and it was also cool to see that Spotify had open-sourced it. I think it is interesting that Spotify is doing this experiment, but also disappointed because I know of at least one company formed by ex-Spotifiers that were trying to build companies on top of Backstage.
Google: The Model Your Site Was Built On Is No Longer Feasible
Hours before Elon Musk closed his deal to buy Twitter, he published an open letter to advertisers. Musk knew that big companies, in particular, were anxious about…
“Free speech” and an advertising-based revenue model are incompatible.
Web3/Decentralized Web/Metaverse
When blockchain emerged, I spent some effort to really understand it. Then I realized that it was a technology searching for a use case fueling a tulip-like baseless speculative market. When Web3 started to emerge, I delayed judgment until I could understand it better. While I believe that there are people who believe that it can fuel a world where creators have more ways to be paid for their work and other such lofty goals, the practicality of it is that very little of those schemes require the blockchain, and most of the people in the space are just trying to make a quick buck before the tulip market collapses.
You’ll probably hear the fuzzy term web3 bandied about in the press if you read tech journalism. Sprinkled around, all these articles are all manner of…
The title says it all.
Crypto and Twitter Are Imploding at the Same Time and It Is Glorious
I’ve been on Mastodon since 2017, but my usage really increased since the acquisition of Twitter. There have been a lot of stories talking about how people are abandoning Mastodon, but even if it doesn’t become what Twitter was, it is still a vibrant community.
There’s No Fixing Meta’s Metaverse, Scrap It, Start Over
I spent 6 years working on the metaverse at Microsoft during the 90s. While the technology has drastically improved, the reason we didn’t get the metaverse back then is that no one could figure out something to do in the metaverse except shoot each other or have sex with each other. All the folks working on metaverse now have learned nothing from the multiple generations of attempts that preceded them. There is still a smug belief that “if you build it, they will come.” The problem is that there is still nothing to do once they show up.
If these problems are intrinsically linked to consolidated tech giants like Meta, Google, and Amazon, why not embrace technologies that decentralize power? This has become a key issue for Brewster Kahle, the 61-year-old founder of the Internet Archive…
Having participated in various forums and working groups for decentralized web stuff over the last few decades, I’m consistently excited by the possibilities and enthusiasm of the folks who work towards those goals and disappointed by their naivete about what people are willing to put up with and how commercial entities are incentivized to coopt and pollute the technologies that do gain some momentum.
Your organization should run its own Mastodon server
Whether you are a large company, a political party, an international news agency, an NGO or a government institution, you should seriously consider running your…
What is the point of having a decentralized web if you don’t own your own part of it?
Twitter Turmoil: We Need an Open Protocol for Public Discourse
Do we want to stay on a social network that shows such callous disregard for its own people? That is the question many of us have been asking as news hit this…
All the agility has been sucked out of agile projects Doing agile is not the same as being agile Agile projects have become bloated, lazy waterfall projects…
One of my biggest pet peeves is people deciding that a bad experience they had with a poorly implemented framework or process must mean that that framework or process is clearly bad and that anyone who had a good experience is lying. So many of the “I was involved in a poorly run agile project and so agile must all be a lie” or “my company tried to do the Spotify model, and it didn’t work; therefore, it must not work at Spotify either” type posts just show the ignorance of their authors and nothing else. While I was worried this article was just another one of those, the author is concerned more about poor agile processes and not agile itself. He even gives some good advice. So worth a read.
Machine Learning
Mozrt, a Deep Learning Recommendation System Empowering Walmart Store Associates with a Personalized Learning Experience
We developed Mozrt, a deep learning recommendation system for Walmart Academy App, the training content portal for Walmart store and Supply Chain associates.
Walmart built a massive technology team in its fight with Amazon. It is good to see them sharing their work.
ChatGPT and the Google and Microsoft chatbots get all the attention now, but before that was GPT3, which also remains the only LLM with the ability to train on your own corpora.
Building Communities
Why Communities Are the New Business Currency | HackerNoon
We’re no longer content with one-way interactions with businesses. We want to feel like…
If you can’t tell from the previous post, I spent some time updating myself on building virtual communities last year. This is a good starting place for folks looking to understand the value.
It needs to be said again, perhaps this time more strongly. Your Blog is The Engine of Community . Dammit. Blog More You are not blogging enough.…
Scott Hanselman thinks developers should be blogging more, and when they do blog, it should be on their own platforms. And he’s right.
Music Industry
I’ve been involved in music as a musician, radio DJ, label owner, and streaming software creator since I was 15. I was delighted to rejoin the music industry in December when I took on the role of CTO at DistroKid.
With 100K tracks uploaded a day, a longtail music cull is coming – Hypebot
Lucian Grainge doesn’t like that people aren’t listening to Universal Artists as much, so he’s putting pressure on the streaming services to remove content he doesn’t think is good. The problem is deciding what content is good and what content is bad. Streamers already remove fraudulent content. So, who decides if your band shouldn’t be on Spotify because you might take a stream away from Justin Bieber (who himself was discovered because he uploaded his songs to YouTube). Gatekeepers are all about protecting their interests at the cost of innovation and getting others a shot.
Why Amazon VP Steve Boom just made the entire music catalog free with Prime
It’s never been clear how much Amazon cares about music streaming as a business. It’s always been an also-ran in the streaming wars that only has listeners because it is an add-on to Prime and is the default service with Alexa. Amazon hasn’t invested much in the service, but maybe that is changing now…
If you think you would like to use these ideas at your company, but you are unsure where to start, I can describe what we did at Avvo. I joined when the company was already nine years old. It had a mostly monolithic architecture running in a single data center with minimal redundancy.
There were some things that we did quickly to move to a more fail-safe world.
Moving from planning around objectives to planning around priorities
First, we worked to build a supportive culture that could handle the inevitable failures better. We moved from planning around specific deliverable commitments to organizing our work around priorities.
Suppose specific achievements, my output, measure my performance. This way of measuring performance often creates problems.
Suppose I need to coordinate with another person, and their commitments do not align to mine. That situation will create tension. If the company’s needs change, but my obligations do not, there is little incentive to reorient my work. To achieve my commitments, I can be thwarted by dependencies or hamper the priorities of the company.
People in leadership like quarterly goals or Managing By Objectives because they create strict accountability. If I commit to doing something and it is not complete when I say it will be, I have failed.
Suppose you think instead about aligning around priorities. In that case, those priorities may change from time to time. Still, if everyone is working against the same set of priorities, you can be sure that they are broadly doing the right things for the company. Aligning to priorities sets an expectation of outcome, not output.
Talk about failure with an eye to future improvement instead of blame
The senior leadership team must be aligned with these approaches. The rest of the organization may not be initially. When leaders talk about failure, they must do it with a learning message rather than blame or punishment. People should know that the expectation is that they may fail. If they are avoiding failure, then they probably aren’t thinking big enough. It is a message that “we want to see you fail, small, and we want to make sure we learn from that failure.”
I created our slack channel to share the lessons from our failures. I sent a message to my organization, making it clear that I don’t expect perfection. I shared my vision that we become a learning organization in town halls and one-on-ones.
Fail-safe architecture
Monoliths are natural when building a new company or when you have a small team. Monoliths are simple to make and more straightforward to deploy when you don’t have multiple teams building together. As the codebase and organization grow, microservices become a better model.
It is critical to recognize the point where a monolith is becoming a challenge instead of an enabler. Microservices require a lot more infrastructure to support them. The effort to transition from one architecture to another is significant, so it is best to prepare before the need becomes urgent.
Avvo had already started moving to a microservices architecture, but lack of investment stalled the transition. I increased investment in the infrastructure team. The team built tools that simplified the effort of creating, testing, monitoring, and deploying services. We then made rapid progress.
In every company, I use the lessons that I have shared in this article to build a culture where teams can innovate and learn from their users. It manifests differently with each group, but every team that has adopted these ideas has improved both business outcomes and employee satisfaction. Work with your peers to adopt some of these ideas. Start small and grow. The process of adopting these concepts mirrors the product development process you are working to build.
If you decide that it isn’t a good fit for your company, you will have failed smart by failing small.
I will leave you with a final thought from Henry Ford.
If you are a long-time Spotify user, you probably won’t recognize the interface shown in the photo below. In May of 2015, though, Spotify was very interested in telling the whole world about it. It was a new set of features in the product called “Spotify Now.”
I lead the engineering effort at Spotify on the Spotify Now set of features. It was the most extensive concerted effort that Spotify had done at the time, involving hundreds of employees across the world.
Spotify Now was a set of features built around bringing the right music for you at any moment in time. The perfect, personalized music for every user for every moment of the day. This effort included adding video, podcasts, the Running feature, a massive collection of new editorial and machine learning generated playlists, and a brand new, simplified user interface for accessing music. It was audacious for a reason. We knew that Apple would launch its Apple Music streaming product soon. We wanted to make a public statement that we were the most innovative platform. Our goal was to take the wind out of Apple’s sails (and sales!)
Given that this was Spotify and many of the things I’ve shared come from Spotify, we understood how to fail smart.
As we launched the project, I reviewed the project retrospective repository. I wanted to see what had and had not worked in large projects before. I was now prepared to make all new mistakes instead of repeating ones from the past.
We had a tight timeline, but some of the features were already in development. I felt confident. However, as we moved forward and the new features started to take shape in the product’s employee releases, there was a growing concern. We worried the new features weren’t going to be as compelling as the vision we had for them. We knew that we, as employees, were not the target users for the features. We were not representative of our users. To truly understand how the functionality would perform, we wanted to follow our product development methods and get the features in front of users to validate our hypotheses.
Publicly releasing the features to a narrow audience was a challenge at that time. The press, also aware of Apple’s impending launch, was watching every Spotify release exceptionally closely. They knew that we tested features, and they were looking for hints of what we would do to counter Apple.
Our marketing team wanted a big launch. This release was a statement, so we wanted a massive spike in Spotify’s coverage extolling our innovation. The press response would be muted if our features leaked in advance of the event.
There was pressure from marketing not to test the features and pressure from product engineering to follow our standard processes. Eventually, we found a compromise. We released early versions of the Spotify Now features to a relatively small cohort of New Zealand users. Satisfied that we were now testing these features in the market, we went back to building Spotify Now and preparing for the launch while waiting for the test results to come back.
After a few weeks, we got fantastic news. For our cohort, retention was 6% higher than the rest of our customer base.
For a subscription-based product like Spotify, customer retention is the most critical metric. It determines the Lifetime Value of the customer. The longer you stay using a subscription product, the more money the company will make from you.
With a company of the scale of Spotify, it was tough to move a core metric like retention significantly. A whole point move was rare and something to celebrate. With Spotify Now, we had a 6% increase! It was massive.
Now, all of our doubt was gone. We knew we were working on something exceptional. We’d validated it in the market! With real people!
On the launch day, Daniel Ek, Spotify’s CEO and founder, Gustav Söderstrom, the Chief Product Officer, and Rochelle King, the head of Spotify’s design organization, shared a stage in New York with famous musicians and television personalities. They walked through everything we had built. It was a lovely event. I shared a stage in the company’s headquarters in Stockholm with Shiva Rajaraman and Dan Sormaz, my product and design peers. We watched the event with our team, celebrating.
As soon as the event concluded, we started the rollout of the new features by releasing them to 1% of our customers in our four largest markets. We’d begun our Ship It phase! We drank champagne and ate prinsesstÃ¥rta.
I couldn’t wait to see how the features were doing in the market. After so much work, I wanted to start the progressive roll out to 100%. Daily, I would stop by the desk of the data scientist who was watching the numbers. For the first couple of days, he would send me away with a comment of “it is too early still. We’re not even close to statistical significance.” Then one day, instead, he said, “It is still too early to be sure, but we’re starting to see the trend take shape, and it doesn’t look like it will be as high as we’d hoped.” Every day after, his expression became dourer. Finally, it was official. Instead of the 6% increase we’d seen in testing, the new features produced a 1% decrease in retention. It was a seven-point difference between what we had tested and what we had launched.
Not only were our new features not enticing customers to stay longer on our platform, but we were driving them away! To say that this was a problem was an understatement. It was a colossal failure.
Now we had a big quandary. We had failed big instead of small. We had released several things together, so it was challenging to narrow down the problem. Additionally, we’d just had a major press event where we talked about all these features. There was coverage all over the internet. The world was now waiting for what we had promised, but we would lose customers if we rolled them out further.
Those results began one of the most challenging summers of our lives. We had to narrow down what was killing our retention in these new features. We started generating hypotheses and running tests within our cohort to find what had gone wrong.
The challenge was that the cohort was too small to run tests quickly (and it was shrinking every day as we lost customers). Eventually, we had to do the math to figure out how much money the company would lose if we expanded the cohort so our tests would run faster. The cost was determined to be justified, and so we grew the cohort to 5% of users in our top four markets.
Gradually, we figured out what in Spotify Now was causing users to quit the product. We removed those features and were able to roll out to the rest of the world with a more modest retention gain.
In the many retrospectives that followed to understand what mistakes we’d made (and what we had done correctly), we found failures in our perceptions of our customers, failures in our teams, and other areas.
It turns out that one of our biggest problems was a process failure. We had a bug in our A/B testing framework. That bug meant that we had accidentally rolled out our test to a cohort participating in a very different trial. A trial to establish a floor on what having no advertising in the free product would do for retention.
To Spotify’s immense credit, rather than punish me, my peers, and the team, instead, we were rewarded for how we handled the failure. The lessons we learned from the mistakes of Spotify Now were immensely beneficial to the company. Those lessons produced some of the company’s triumphs in the years that have followed, including Spotify’s most popular curated playlists, Discover Weekly, Release Radar, Daily Mixes, and podcasts.
How do we reduce the fuel-air bomb failure into an internal combustion failure? How can we fail safely?
Minimizing the cost of failure
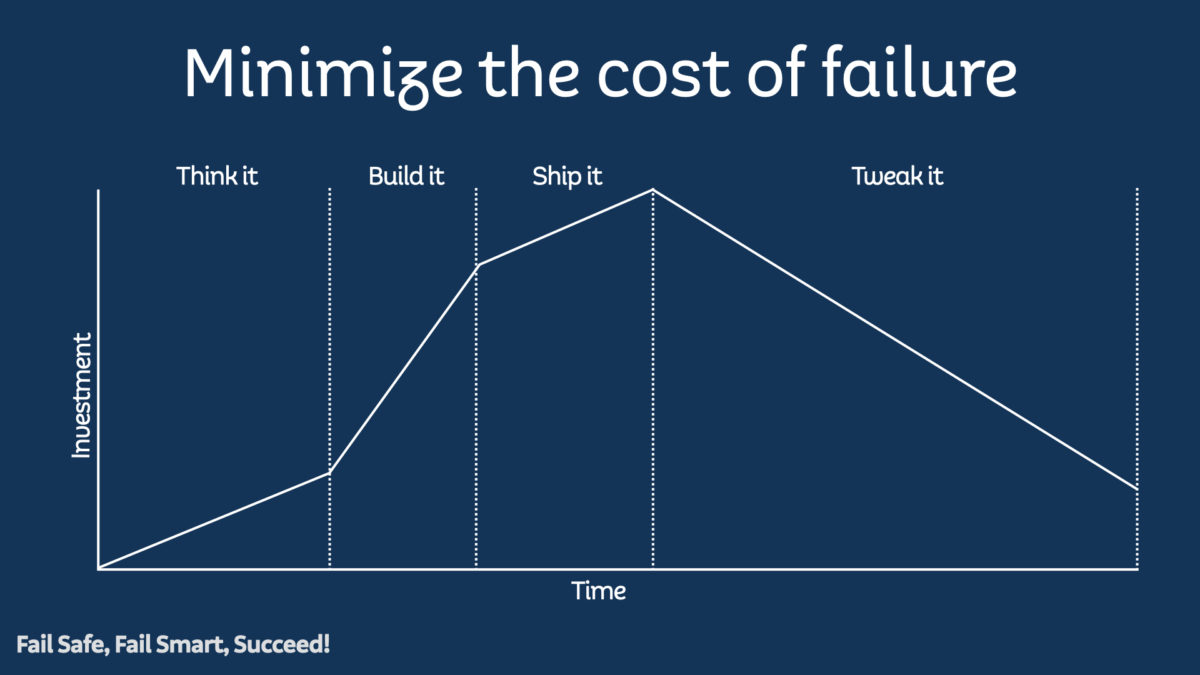
If you fail quickly, you are reducing the cost in time, equipment, and expenses. At Spotify, we had a framework, rooted in Lean Startup, that we used to reduce the cost of our failures. We named the framework “Think it, Build it, Ship it, Tweak it.“
This graph shows investment into a feature over time through the different phases of the framework. Investment here signifies people’s time, material costs, equipment, opportunity cost, whichever.
Think It
Imagine this scenario: you are coming back from lunch with some people you work with, and you have an idea for a new feature. You discuss it with your product owner, and they like the idea. You decide to explore if it would be a useful feature for the product. You have now entered the “Think It” phase. During this phase, you may work with the Product Owner and potentially a designer. This phase represents a part-time effort by a small subset of the team–a small investment.
You might create some paper prototypes to test out the idea with the team and with customers. You may develop some lightweight code prototypes. You may even ship a very early version of the feature to some users. The goal is to test as quickly and cheaply as possible and gather some real data on the feature’s viability.
You build a hypothesis on how the feature can positively impact the product, tied to real product metrics. This hypothesis is what you will validate against at each stage of the framework.
If the early data shows that the feature isn’t needed or wanted by customers, your hypothesis is incorrect. You have two choices. You may iterate and try a different permutation of the concept, staying in the Think It phase and keeping the investment low. You may decide that it wasn’t as good an idea as you hoped and end the effort before investing further.
If you decide to end during the Think It phase, congratulations! You’ve saved the company time and money building something that wasn’t necessary. Collect the lessons in a retrospective and share them so that everyone else can learn.
Build It
The initial tests look promising. The hypothesis isn’t validated, but the indicators warrant further investment. You have some direction from your tests for the first version of the feature.
Now is the time to build the feature for real. The investment increases substantially as the rest of the team gets involved.
How can you reduce the cost of failure in the Build It phase? You don’t build the fully realized conception of the feature. You develop the smallest version that will validate your initial hypothesis, the MVP. Your goal is validation with the broader customer set.
The Build It phase is where many companies I speak to get stuck. If you have the complete product vision in your head, finding the minimal representation seems like a weak concept. Folks in love with their ideas have a hard time finding the core element that validates the whole. Suppose the initial data that comes back for the MVP puts the hypothesis into question. In that case, it is easier to question the validity of the MVP than to examine the hypothesis’s validity. This issue of MVP is usually the most significant source of contention in the process.
It takes practice to figure out how to formulate a good MVP, but the effort is worth it. Imagine if the Clippy team had been able to ship an MVP. Better early feedback could have saved many person-years and millions of dollars. In my career, I have spent years (literally) building a product without shipping it. Our team’s leadership shifted product directions several times without ever validating or invalidating any of their hypotheses in the market. We learned nothing about the product opportunity, but the development team learned a lot about refactoring and building modular code.
Even during the Build It phase, there are opportunities to test the hypothesis: early internal releases, beta tests, user tests, and limited A/B tests can all be used to provide direction and information.
Ship It
Your MVP is ready to release to your customers! The validation with the limited release pools and the user testing shows that your hypothesis may be valid–time to ship.
In many, if not most, companies shipping a software release is still a binary thing. No users have it, and now all users have it. This approach robs you of an opportunity to fail cheaply! Your testing in Think It and Build It may have shown validation for your hypothesis. It may have also provided incorrect information, or you may have misinterpreted it. On the technical side, whatever you have done to this point will not have validated that your software performs correctly at scale.
Instead of shipping instantly to one hundred percent of your users, do a progressive rollout. At Spotify, we had the benefit of a fairly massive scale. This scale allowed us to ship to 1%, 5%, 10%, 25%, 50%, and then 99% of our users (we usually held back 1% of our users as a control group for some time). We could do this rollout relatively quickly while maintaining statistical significance due to our size.
If you have a smaller user base, you can still do this with fewer steps and get much of the value.
At each stage of the rollout, we’d use the product analytics to see if we were validating our assumptions. Remember that we always tied the hypothesis back to product metrics. We’d also watch our systems to make sure that they were handling the load appropriately and didn’t have any other technical issues or bugs arising.
If the analytics showed that we weren’t improving the product, we had two decisions again. Should we iterate and try different permutations of the idea, or should we stop and remove the feature?
Usually, if we reached this point, we would iterate, keeping to the same percentage of users. If this feature MVP wasn’t adding to the product, it took away from it, so rolling out further would be a bad idea. This rollout process was another way to reduce the cost of failure. It reduced the percentage of users seeing a change that may negatively affect product metrics. Sometimes, iterating and testing with a subset of users would give us the necessary direction to move forward with a better version of the MVP. Occasionally, we would realize that the hypothesis was invalid. We would then remove the feature (which is just as hard to do as you imagine, but it was more comfortable with the data validating the decision).
If we removed the feature during the Ship It phase, we would have wasted time and money. We still would have wasted a lot less than if we’d released a lousy feature to our entire customer base.
Tweak It
The shaded area under this graph shows the investment to get a feature to customers. You earn nothing against the investment until the feature’s release to all your customers. Until that point, you are just spending. The Think It/Ship It/Build It/Tweak It framework aims to reduce that shaded area; to reduce the amount of investment before you start seeing a return.
You have now released the MVP for the feature to all your customers. The product metrics validate the hypothesis that it is improving the product. You are now ready for the next and final phase, Tweak It.
The MVP does not realize the full product vision, and the metrics may be positive but not to the level of your hypothesis. There is a lot more opportunity here!
The result of the Ship It phase represents a new baseline for the product and the feature. The real-world usage data, customer support, reviews, forums, and user research can now inform your next steps.
The Tweak It phase represents a series of smaller Think It/Build It/Ship It/Tweak It efforts. From now, your team iteratively improves the shipped version of the feature and establishes new, better baselines. These efforts will involve less and less of the team over time, and the investment will decrease correspondingly.
When iterating, occasionally, you reach a local maximum. Your tweaks will result in smaller and smaller improvements to the product. Once again, you have two choices: move on to the next feature or look for another substantial opportunity with the current feature.
The difficulty is recognizing that there may be a much bigger opportunity nearby. When you reach this decision point, it can be beneficial to try a big experiment. You may also choose to take a step back and look for an opportunity that might be orthogonal to the original vision but could provide a significant improvement.
You notice in the graph that the investment never reaches zero. This gap reveals the secret, hidden, fifth step of the framework.
Maintain It
Even if there is no active development on a feature, it doesn’t mean that there isn’t any investment into it. The feature still takes up space in the product. It consumes valuable real estate in the UI. Its code makes adding other features harder. Library or system updates break it. Users find bugs. Writers have to maintain documentation about the functionality.
The investment cost means that it is critical not to add features to a product that do not demonstrably improve it. There is no such thing as a zero-cost feature. Suppose new functionality adds nothing to the product in terms of incremental value to users. In that case, the company must invest in maintaining it. Features that bring slight improvements to core metrics may not be worth preserving, given the additional complexity they add.
Expect failure all the time
When you talk about failure in the context of software development from the year 2000 to now, there is a substantial difference. Back then, you worked hard to write robust software, but the hardware was expected to be reasonably reliable. When there was a hardware failure, the software’s fault tolerance was of incidental importance. You didn’t want to cause errors yourself, but if the platform was unstable, there wasn’t much you were expected to do about it.
Today we live in a world with public clouds and mobile platforms where the environment is entirely beyond our control. AWS taught us a lot about how to handle failure in systems. This blog post from Netflix about their move to AWS was pivotal to the industry’s adapting to the new world.
Netflix’s approach to system design has been so beneficial to the industry. We assume that everything can be on fire all the time. You could write perfect software, and the scheduler is going to come and kill it on mobile. AWS will kill your process, and your service will be moved from one pod to another with no warning. We now write our software expecting failure to happen at any time.
We’ve learned that writing big systems makes handling failure complicated, so micro-service architectures have become more prevalent. Why? Because they are significantly more fault-tolerant, and when they fail, they fail small. Products like Amazon, Netflix, or Spotify all have large numbers of services running. A customer doesn’t notice if one or more instances of the services fail. When a service fails in those environments, the service is responsible for a small part of the experience; the other systems assume that it can fail. There are things like caching to compensate for a system disappearing.
Netflix has its famous chaos monkey testing, which randomly kills services or even entire availability zones. These tests make sure that their systems fail well.
Having an architecture composed of smaller services that are assumed to fail means that there is near zero user impact when there is a problem. Failing well is critical for these services and their user experience.
Smaller services also make it possible to use progressive rollout, feature flags, dark loading, blue-green deploys, and canary instances, making it easier to build in a fail-safe way.
If innovation requires failure, to build an innovative product or company, how your culture handles the inevitable failures is key to creating a fail-safe environment.
Many companies still punish projects or features that do not succeed. The same companies then wonder why their employees are so risk-averse. Punishing failure can take many forms, both obvious and subtle. Punishment can mean firing the team or leader who created an unsuccessful release or project. Sanctions are often more subtle:
Moving resources away from innovative efforts that don’t yield immediate successes.
Allowing people to ridicule failed efforts.
Continuing to invest in the slow, steady, growth projects instead of the more innovative but risky efforts. Innovator’s dilemma is just the most well-known aspect of this.
Breeding innovation out
I spend several years working at a company whose leadership was constantly extorting the employees to be more innovative and take more risks. It created ever-new processes to encourage new products to come from within the organization. It was also a company that had always grown through acquisition. Every year, it would acquire new companies. At the start of the next year’s budget process, there would inevitably be the realization that the company had now grown too large. Nearly every year, there would be a layoff.
If you are a senior leader and need to trim ten percent of your organization, where would you look? In previous years, you likely had already eliminated your lowest performers. Should you reduce the funding of the products that bring in your revenue or kill the new products that are struggling to make their first profit? The answer is clear if your bonus and salary are dependent on hitting revenue targets.
Through the culture of the company, it communicated that taking risks was detrimental to a career. So the company lost its most entrepreneurial employees either through voluntary or involuntary attrition. Because it could not innovate within, innovation could only happen through acquisitions, perpetuating the cycle.
If failure is punished, and failure is necessary for innovation, then punishing failure, either overtly or subtly, means that you are dis-incentivizing innovation.
Don’t punish failure. Punish not learning from failure. Punish failing big when you could have failed small first. Better yet, don’t punish at all. Reward the failures that produce essential lessons for the company and that the team handles well. Reward risk-taking if you want to encourage innovation.
Each failure allows you to learn many things. Take the time to learn those lessons
Learning from failure
It can be hard to learn the lessons from failure. When you fail, your instinct is to move on, to sweep it under the rug. You don’t want to wallow in your mistakes. However, if you move on too quickly, you miss the chance to gather all the lessons, which will lead to more failure instead of the success you’re seeking.
Lessons from failure: Your process
Sometimes the failure was in your process. The following exchange is fictional, but I’ve heard something very much like it more than once in my career.
“What happened with this release? Customers are complaining that it is incredibly buggy.”
“Well, the test team was working on a different project, so they jumped into this one late. We didn’t want to delay the release, so we cut the time for testing short and didn’t catch those issues. We had test automation, and it caught the issue, but there have been a lot of false positives, so no one was watching the results.”
“Did we do a beta test for this release? An employee release?”
“No.”
The above conversation indicates a problem with the software development process (and, for this specific example, a bit of a culture-of-quality problem). If you’ve ever had an exchange like the one above, what did you do to solve the underlying issues? If the answer is “not much,” you didn’t learn enough from the failure, and you likely had similar problems afterward.
Lessons from failure: your team
Sometimes your team is a significant factor in a failure. I don’t mean that the members of the group aren’t good at their jobs. Your team may be missing a skillset or have personality conflicts. Trust may be an issue within the team, and so people aren’t open with each other.
“The app is performing incredibly slowly. What is going on?”
“Well, we inherited this component that uses this data store, and no one on the team understands it. We’re learning it as we’re doing it, and it has become a performance problem.”
Suppose the above exchange happened in your team. In that case, you might make sure that the next time you decide to use (or inherit) a technology, you make sure that someone on the team knows it well, even if that means adding someone to the team.
Lessons from failure: your perception of your customers
A vein of failure, and a significant one in the lesson of Clippy, is having an incorrect mental model for your customer.
We all have myths about who our customers are. Why do I call them “myths”? The reason is that you can’t precisely read the minds of every one of your customers. At the beginning of a product’s life cycle, you may know each of your customers well when there are few of them. That condition, hopefully, will not last very long.
How do you build a model of your user? You do user research, talk to your customer service team, beta test, and read app reviews and tweets about your product. You read your product forums. You instrument your app and analyze user behavior.
We have many different ways of interacting with the subsets of our customers. Those interactions give us the feeling that we know what they want or who they are.
These interactions provide insights into your customers as an aggregate. They also fuel myths of who our customers are because they are a sampling of the whole. We can’t know all our customers, so we create personas in our minds or collectively for our team.
Suppose you have a great user research team, and you are very rigorous in your effort to understand your customers. You may be able to have in-depth knowledge about your users and their needs for your product. However, that knowledge and understanding will only be for a moment in time. Your product continues to evolve and change and hopefully add new users often. Your new customers come to your product because of the unique problems they can solve. Those problems are different from the existing users—your perception of your customers ages quickly. You are now building for who they were, not who they are.
Lessons from failure: your understanding of your product
You may think you understand your product; after all, you are the one who is building it! However, the product that your customers are using may be different from the product you are making.
You build your product to solve a problem. In your effort to solve that problem, you may also solve other problems for your customers that you didn’t anticipate. Your customers are delighted that they can solve this problem with your product. In their minds, this was a deliberate choice on your part.
Now you make a change that improves the original problem’s solution but breaks the unintended use case. Your customers are angry because you ruined their product!
Lessons from failure: yourself
Failure gives you a chance to learn more about yourself. Is there something you could do differently next time? Was there an external factor that is obvious in hindsight but could have been caught earlier if you approached things differently?
Our failures tend to be the hardest to dwell on. Our natural inclination is to find fault externally to console ourselves. It is worth taking some time to reflect on your performance. You will always find something that you can do that will help you the next time.
Collecting the lessons: Project Retrospectives
The best way that I have learned to extract the lessons is to do a project retrospective.
A project retrospective aims to understand what happened in the project from its inception to its conclusion. You are looking to understand each critical decision, what informed the decision, and its outcome.
In a project retrospective, you are looking for the things that went wrong, the things that went well, and the things that went well, but you could do better the next time. The output of the retrospective is neutral. It is not for establishing blame or awarding kudos. It exists to make sure you learn. For this reason, it is useful for both unsuccessful and highly successful projects.
A good practice for creating a great culture around failure is to make it the general custom to have a retrospective at the end of every project in your company. Having retrospectives only for the unsuccessful projects perpetuates a blame culture.
Since the project retrospectives are blameless, it is good to share them within your company. Create a project retrospective repository and publicize it.
The repository becomes a precious resource for everyone in your company. It shows what has worked and what has been challenging in your environment. It allows your teams to avoid making the mistakes of the past. We always want to be making new mistakes, not old ones!
The repository is also handy for new employees to teach them about how projects work in your company. Finally, it is also a resource for documenting product decisions.
The retrospective repository is a valuable place to capture the history of your products and your process.
Spotify’s failure-safe culture
I learned a lot about creating a failure safe culture when I worked at Spotify. Some of the great examples of this culture were:
One of the squads created a “Fail Wall” to capture the things they were learning. The squad didn’t hide the wall. It was on a whiteboard facing the hallway where everyone could see it.
This document is a report from one of the project retrospectives. You don’t need any special software for the record. For us, it was just a collection of Google docs in a shared folder.
One of the agile coaches created a slack channel for teams to share the lessons learned from failures with the whole company.
Spotify’s CTO posted an article encouraging everyone to celebrate the lessons that they learned from failure. Which inspired other posts like this:
If you look at the Spotify engineering blog, there are probably more posts about mistakes that we made than cool things we did in the years I worked there (2013-2016).
These kinds of posts are also valuable to the community. Often, when you are searching for something, it is because you are having a problem. We might have had the same issue. These posts are also very public expressions of the company culture.
Failure as a competitive advantage
We’re all going to fail. If my company can fail smart and fast, learning from our mistakes; while your company ignores the lessons from failure, my company will have a competitive advantage.
This article is about failure and everything I’ve learned from 28 years of failing (and succeeding) in the technology industry. Its basis is my talk of the same name that I first gave in 2015.
I’ve broken it into five parts to make it easier to read and share:
How we approach failure is critical in any industry, but it is especially crucial in building software.
Why?
The answer is simple: invention requires failure.
We don’t acknowledge that fact enough as an industry. Not broadly. It is something we should recognize and understand more. As technologists, we are continually looking for ways to transform existing businesses or build new products. We are an industry that grows on innovation and invention.
Real innovation is creating something uniquely new. If you can create something genuinely novel without failing a few times along the way, it probably isn’t very innovative. Albert Einstein expressed this as “Anyone who has never made a mistake has never tried anything new.”
In his own words, Thomas Edison says that he created three thousand different theories before he found the right materials for his electric light. To invent his battery, the laboratory performed over ten thousand experiments.
Filmmaker Kevin Smith says, “failure is success training.” I like that sentiment. It frames failure as leading to success.
Failure teaches you the things you need to know to succeed. Stated more strongly: failure is a requirement for success.
Creating a fail-safe environment
To achieve success, what’s important isn’t how to avoid failure; it’s how to handle failure when it comes. The handling of failure makes the difference between eventual success and never succeeding. Creating conditions conducive to learning from failure means creating a fail-safe environment.
In the software industry, we define a fail-safe environment as setting up processes to avoid failure. Instead, we should ensure that when the inevitable failure happens, we handle it well and reduce its impact. We want to fail smart.
When I was at Spotify, a company that worked hard to create a fail-smart environment, we described this as “minimizing the blast radius.” This quote from Mikael Krantz, the head architect at Spotify during that time, sums up the idea nicely: “we want to be an internal combustion engine, not a fuel-air bomb. Many small, controlled explosions, propelling us in a generally ok direction, not a huge blast leveling half the city.”
So, let us plan for failure. Let’s embrace the mistakes that are going to come in the smartest way possible. We can use those failures to move us forward and make sure that they are small enough not to take out the company. I like the combustion engine analogy because it embraces that failure, well-handled, pushes us in the right direction. If we anticipate, we can course correct and continue to move forward.
One way you can create these small, controlled explosions is to fail fast. Find the fastest, most straightforward path to learning. Can you validate your idea quickly? Can you reduce the concept down so that you can get it in front of real people immediately and get feedback before investing in a bunch of work? Failing fast is one of the critical elements of the Lean Startup methodology.
A side benefit of small failures is that they are easier to understand. You can identify what happened and learn from it. With a big failure, you must unpack and dig in to know where things went wrong.
I worked at Microsoft when the company created Office Assistant. Although I didn’t work on that team, I knew a few people who did.
It is easy to think that the Office Assistant was a horrible idea created by a group of poor-performing developers and product people, but that couldn’t be farther from the truth. Extremely talented developers, product leads, researchers with fantastic track records, and PhDs from top-tier universities built Clippy. People who thought they understood the market and their users. These world-class people were working on one of (if not THE) most successful software products of all-time at the apex of its popularity. Microsoft spent millions of dollars and multiple person-years on the development of Clippy.
So, what happened?
What happened is that those brilliant people were wrong. Very wrong, as all of us are from time to time. How could they have found their mistake before releasing widely? It wasn’t easy at the time to test product assumptions. It was much harder to validate hypotheses about users and their needs.
How we used to release software
Way back before we could assume high-bandwidth internet connections, we wrote and shipped software in a very different way.
Software products were manufactured, transcribed onto plastic and foil discs. For a release like Microsoft Office, those discs were manufactured in countries worldwide, put into boxes, then put onto trucks and trains and shipped to warehouses, like TV sets. From there, trucks would take them to stores where people would purchase them in person, take them home and spend an afternoon swapping the discs in and out of their computers, installing the software.
With a release like Office, Microsoft would need massive disc pressing capability. It required dozens of CD/DVD plants across the world to work simultaneously. That capability had to be booked years in advance. Microsoft would pay massive sums of money to take over the entire CD/DVD pressing industry essentially. This monopolization of disc manufacturing required a fixed duration. Moving or growing that window was monstrously expensive.
It was challenging to validate a new feature in that atmosphere, peculiarly if that feature was a significant part of a release that you didn’t want to leak to the press.
That was then; this is now.
Today, the world is very different. There is no excuse for not validating your ideas.
You can now deploy your website every time you hit save in your editor. You can ship your mobile app multiple times per week. You can try ideas almost as fast as you can think of them. You can try and fail and learn from the failure and make your product better continuously.
Thomas J Watson, the CEO of IBM from 1914 until 1956, said, “If you want to increase your success rate, double your failure rate.” If it takes you years and millions of dollars to fail and you want to double that, your company will not survive to see the eventual success. Failing Fast minimizes the impact of your failure by reducing the cost and delay in learning.
I worked at an IBM research lab a long time ago. I was a developer on a project building early versions of synchronized streaming media. After over a year of effort, we arranged to publish our work. As we prepared, we learned there were two other labs at IBM working on the same problems. We were done, it was too late to collaborate. At the time, it seemed to me like big-company stupidity, not realizing that three different teams were working on the same thing. Later I realized that this was a deliberate choice. It was how IBM failed fast. Since it took too long to fail serially, IBM had become good at failing in parallel.
One of my family’s quarantine projects is re-assembling all my daughter’s old Lego sets. The pieces from the sets are in several large storage totes, mixed at random from years of building and taking things apart. As I was digging through a box today looking for some specific piece, I started noticing the system I had started to use.
As I looked for a piece, I would start to collect identical pieces and join them up. Joining pieces allows me later to find those pieces later more efficiently, even if I put them back into the box. It also reduced the number of pieces I would have to sort through to find anything. I do this unconsciously because I have done this ever since I was a kid.
Today I realized that this was a perfect metaphor for paying down technical debt.
Grouping the Legos as you are building means that you take a little bit longer on the sets you make at the beginning, but each successive set gets faster. Not only are there fewer Legos to sort through, but the Legos that are there are becoming more and more organized.
When working in a code base that has accumulated a lot of technical or architectural debt, cleaning things up as you go means that your velocity increases over time. Ignoring technical debt is like adding a few random Legos to the box as you take pieces out. Not only does it not get simpler or faster. It gets slower. Eventually, you have to go to the store to buy a new set because it is just easier than finding the pieces for the old one. Or worse, you have to go to eBay and pay twice as much for the same set because Lego stopped manufacturing it. (I am probably abusing the metaphor here.)
I’ve also been thinking about the difference between building a set by pulling out Legos from a big box versus building a brand-new set.
When you build a new set, the pieces come in smaller bags. Lego numbers the bags, so you only need to open one at a time to find the parts you need. Bigger sets may have multiple instruction books, also ordered by number.
The grouping of Lego pieces into bags is a metaphor for Agile software development.
By narrowing the scope and limiting the options, you make the work go faster, even when the problem is involved (like one of their expert models).
The next time you are trying to explain to your product manager (or anyone) why you need to add more tech-debt stories into the backlog even though it means a feature will take longer to deliver, bring in a big box of Legos as a teaching tool. If it doesn’t work, you’ll at least have a fun team meeting…