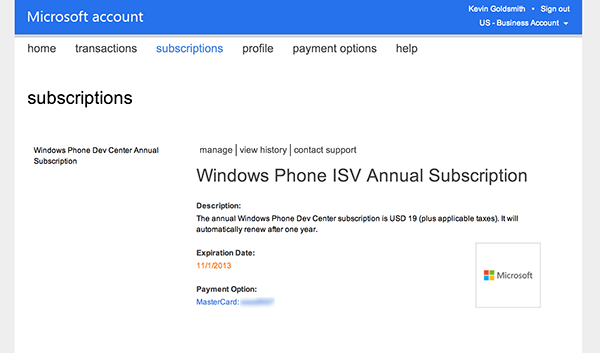
This article is about failure and everything I’ve learned from 28 years of failing (and succeeding) in the technology industry. Its basis is my talk of the same name that I first gave in 2015.
I’ve broken it into five parts to make it easier to read and share:
- Part One: Why Focus on Failure?
- Part Two: Building a Fail-Safe Culture
- Part Three: Making Failure Safer
- Part Four: My Biggest Failure
- Part Five: Putting it into Practice
The importance of failure in software development
How we approach failure is critical in any industry, but it is especially crucial in building software.
Why?
The answer is simple: invention requires failure.

We don’t acknowledge that fact enough as an industry. Not broadly. It is something we should recognize and understand more. As technologists, we are continually looking for ways to transform existing businesses or build new products. We are an industry that grows on innovation and invention.
Real innovation is creating something uniquely new. If you can create something genuinely novel without failing a few times along the way, it probably isn’t very innovative. Albert Einstein expressed this as “Anyone who has never made a mistake has never tried anything new.”

In his own words, Thomas Edison says that he created three thousand different theories before he found the right materials for his electric light. To invent his battery, the laboratory performed over ten thousand experiments.
Filmmaker Kevin Smith says, “failure is success training.” I like that sentiment. It frames failure as leading to success.
Failure teaches you the things you need to know to succeed. Stated more strongly: failure is a requirement for success.
Creating a fail-safe environment
To achieve success, what’s important isn’t how to avoid failure; it’s how to handle failure when it comes. The handling of failure makes the difference between eventual success and never succeeding. Creating conditions conducive to learning from failure means creating a fail-safe environment.
In the software industry, we define a fail-safe environment as setting up processes to avoid failure. Instead, we should ensure that when the inevitable failure happens, we handle it well and reduce its impact. We want to fail smart.
When I was at Spotify, a company that worked hard to create a fail-smart environment, we described this as “minimizing the blast radius.” This quote from Mikael Krantz, the head architect at Spotify during that time, sums up the idea nicely: “we want to be an internal combustion engine, not a fuel-air bomb. Many small, controlled explosions, propelling us in a generally ok direction, not a huge blast leveling half the city.”

So, let us plan for failure. Let’s embrace the mistakes that are going to come in the smartest way possible. We can use those failures to move us forward and make sure that they are small enough not to take out the company. I like the combustion engine analogy because it embraces that failure, well-handled, pushes us in the right direction. If we anticipate, we can course correct and continue to move forward.
One way you can create these small, controlled explosions is to fail fast. Find the fastest, most straightforward path to learning. Can you validate your idea quickly? Can you reduce the concept down so that you can get it in front of real people immediately and get feedback before investing in a bunch of work? Failing fast is one of the critical elements of the Lean Startup methodology.
A side benefit of small failures is that they are easier to understand. You can identify what happened and learn from it. With a big failure, you must unpack and dig in to know where things went wrong.
The Lesson of Clippy

Even if you’ve never used the Office Assistant feature of Microsoft Office, you are likely aware of it. It was a software product flop so massive that it became a part of pop culture.
I worked at Microsoft when the company created Office Assistant. Although I didn’t work on that team, I knew a few people who did.
It is easy to think that the Office Assistant was a horrible idea created by a group of poor-performing developers and product people, but that couldn’t be farther from the truth. Extremely talented developers, product leads, researchers with fantastic track records, and PhDs from top-tier universities built Clippy. People who thought they understood the market and their users. These world-class people were working on one of (if not THE) most successful software products of all-time at the apex of its popularity. Microsoft spent millions of dollars and multiple person-years on the development of Clippy.
So, what happened?
What happened is that those brilliant people were wrong. Very wrong, as all of us are from time to time. How could they have found their mistake before releasing widely? It wasn’t easy at the time to test product assumptions. It was much harder to validate hypotheses about users and their needs.
How we used to release software
Way back before we could assume high-bandwidth internet connections, we wrote and shipped software in a very different way.
Software products were manufactured, transcribed onto plastic and foil discs. For a release like Microsoft Office, those discs were manufactured in countries worldwide, put into boxes, then put onto trucks and trains and shipped to warehouses, like TV sets. From there, trucks would take them to stores where people would purchase them in person, take them home and spend an afternoon swapping the discs in and out of their computers, installing the software.
With a release like Office, Microsoft would need massive disc pressing capability. It required dozens of CD/DVD plants across the world to work simultaneously. That capability had to be booked years in advance. Microsoft would pay massive sums of money to take over the entire CD/DVD pressing industry essentially. This monopolization of disc manufacturing required a fixed duration. Moving or growing that window was monstrously expensive.
It was challenging to validate a new feature in that atmosphere, peculiarly if that feature was a significant part of a release that you didn’t want to leak to the press.
That was then; this is now.
Today, the world is very different. There is no excuse for not validating your ideas.
You can now deploy your website every time you hit save in your editor. You can ship your mobile app multiple times per week. You can try ideas almost as fast as you can think of them. You can try and fail and learn from the failure and make your product better continuously.

Thomas J Watson, the CEO of IBM from 1914 until 1956, said, “If you want to increase your success rate, double your failure rate.” If it takes you years and millions of dollars to fail and you want to double that, your company will not survive to see the eventual success. Failing Fast minimizes the impact of your failure by reducing the cost and delay in learning.
I worked at an IBM research lab a long time ago. I was a developer on a project building early versions of synchronized streaming media. After over a year of effort, we arranged to publish our work. As we prepared, we learned there were two other labs at IBM working on the same problems. We were done, it was too late to collaborate. At the time, it seemed to me like big-company stupidity, not realizing that three different teams were working on the same thing. Later I realized that this was a deliberate choice. It was how IBM failed fast. Since it took too long to fail serially, IBM had become good at failing in parallel.