
Fail Safe, Fail Smart, Succeed!
- Part One: Why Focus on Failure?
- Part Two: Building a Fail-Safe Culture
- Part Three: Making Failure Safer
- Part Four: My Biggest Failure
- Part Five: Putting it into Practice
Making Failure Safer
How do we reduce the fuel-air bomb failure into an internal combustion failure? How can we fail safely?
Minimizing the cost of failure

If you fail quickly, you are reducing the cost in time, equipment, and expenses. At Spotify, we had a framework, rooted in Lean Startup, that we used to reduce the cost of our failures. We named the framework “Think it, Build it, Ship it, Tweak it.“
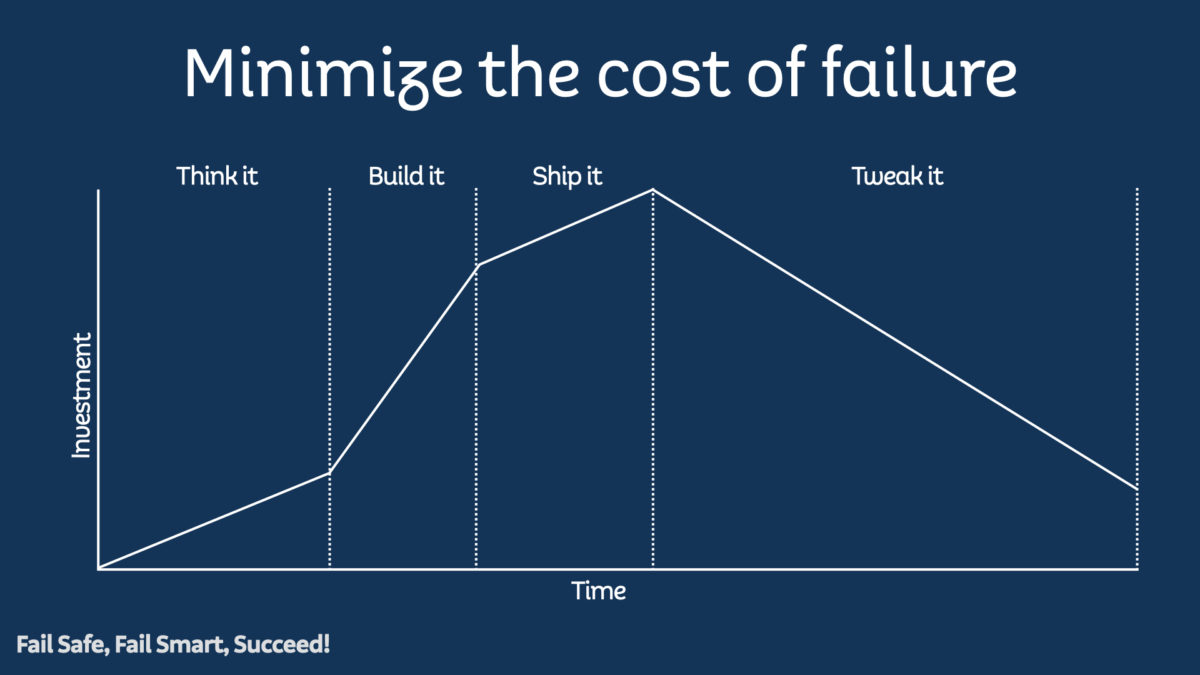
This graph shows investment into a feature over time through the different phases of the framework. Investment here signifies people’s time, material costs, equipment, opportunity cost, whichever.
Think It
Imagine this scenario: you are coming back from lunch with some people you work with, and you have an idea for a new feature. You discuss it with your product owner, and they like the idea. You decide to explore if it would be a useful feature for the product. You have now entered the “Think It” phase. During this phase, you may work with the Product Owner and potentially a designer. This phase represents a part-time effort by a small subset of the team–a small investment.
You might create some paper prototypes to test out the idea with the team and with customers. You may develop some lightweight code prototypes. You may even ship a very early version of the feature to some users. The goal is to test as quickly and cheaply as possible and gather some real data on the feature’s viability.
You build a hypothesis on how the feature can positively impact the product, tied to real product metrics. This hypothesis is what you will validate against at each stage of the framework.
If the early data shows that the feature isn’t needed or wanted by customers, your hypothesis is incorrect. You have two choices. You may iterate and try a different permutation of the concept, staying in the Think It phase and keeping the investment low. You may decide that it wasn’t as good an idea as you hoped and end the effort before investing further.
If you decide to end during the Think It phase, congratulations! You’ve saved the company time and money building something that wasn’t necessary. Collect the lessons in a retrospective and share them so that everyone else can learn.
Build It
The initial tests look promising. The hypothesis isn’t validated, but the indicators warrant further investment. You have some direction from your tests for the first version of the feature.
Now is the time to build the feature for real. The investment increases substantially as the rest of the team gets involved.
How can you reduce the cost of failure in the Build It phase? You don’t build the fully realized conception of the feature. You develop the smallest version that will validate your initial hypothesis, the MVP. Your goal is validation with the broader customer set.
The Build It phase is where many companies I speak to get stuck. If you have the complete product vision in your head, finding the minimal representation seems like a weak concept. Folks in love with their ideas have a hard time finding the core element that validates the whole. Suppose the initial data that comes back for the MVP puts the hypothesis into question. In that case, it is easier to question the validity of the MVP than to examine the hypothesis’s validity. This issue of MVP is usually the most significant source of contention in the process.
It takes practice to figure out how to formulate a good MVP, but the effort is worth it. Imagine if the Clippy team had been able to ship an MVP. Better early feedback could have saved many person-years and millions of dollars. In my career, I have spent years (literally) building a product without shipping it. Our team’s leadership shifted product directions several times without ever validating or invalidating any of their hypotheses in the market. We learned nothing about the product opportunity, but the development team learned a lot about refactoring and building modular code.
Even during the Build It phase, there are opportunities to test the hypothesis: early internal releases, beta tests, user tests, and limited A/B tests can all be used to provide direction and information.
Ship It
Your MVP is ready to release to your customers! The validation with the limited release pools and the user testing shows that your hypothesis may be valid–time to ship.
In many, if not most, companies shipping a software release is still a binary thing. No users have it, and now all users have it. This approach robs you of an opportunity to fail cheaply! Your testing in Think It and Build It may have shown validation for your hypothesis. It may have also provided incorrect information, or you may have misinterpreted it. On the technical side, whatever you have done to this point will not have validated that your software performs correctly at scale.
Instead of shipping instantly to one hundred percent of your users, do a progressive rollout. At Spotify, we had the benefit of a fairly massive scale. This scale allowed us to ship to 1%, 5%, 10%, 25%, 50%, and then 99% of our users (we usually held back 1% of our users as a control group for some time). We could do this rollout relatively quickly while maintaining statistical significance due to our size.
If you have a smaller user base, you can still do this with fewer steps and get much of the value.
At each stage of the rollout, we’d use the product analytics to see if we were validating our assumptions. Remember that we always tied the hypothesis back to product metrics. We’d also watch our systems to make sure that they were handling the load appropriately and didn’t have any other technical issues or bugs arising.
If the analytics showed that we weren’t improving the product, we had two decisions again. Should we iterate and try different permutations of the idea, or should we stop and remove the feature?
Usually, if we reached this point, we would iterate, keeping to the same percentage of users. If this feature MVP wasn’t adding to the product, it took away from it, so rolling out further would be a bad idea. This rollout process was another way to reduce the cost of failure. It reduced the percentage of users seeing a change that may negatively affect product metrics. Sometimes, iterating and testing with a subset of users would give us the necessary direction to move forward with a better version of the MVP. Occasionally, we would realize that the hypothesis was invalid. We would then remove the feature (which is just as hard to do as you imagine, but it was more comfortable with the data validating the decision).
If we removed the feature during the Ship It phase, we would have wasted time and money. We still would have wasted a lot less than if we’d released a lousy feature to our entire customer base.

Tweak It
The shaded area under this graph shows the investment to get a feature to customers. You earn nothing against the investment until the feature’s release to all your customers. Until that point, you are just spending. The Think It/Ship It/Build It/Tweak It framework aims to reduce that shaded area; to reduce the amount of investment before you start seeing a return.
You have now released the MVP for the feature to all your customers. The product metrics validate the hypothesis that it is improving the product. You are now ready for the next and final phase, Tweak It.
The MVP does not realize the full product vision, and the metrics may be positive but not to the level of your hypothesis. There is a lot more opportunity here!
The result of the Ship It phase represents a new baseline for the product and the feature. The real-world usage data, customer support, reviews, forums, and user research can now inform your next steps.
The Tweak It phase represents a series of smaller Think It/Build It/Ship It/Tweak It efforts. From now, your team iteratively improves the shipped version of the feature and establishes new, better baselines. These efforts will involve less and less of the team over time, and the investment will decrease correspondingly.
When iterating, occasionally, you reach a local maximum. Your tweaks will result in smaller and smaller improvements to the product. Once again, you have two choices: move on to the next feature or look for another substantial opportunity with the current feature.
The difficulty is recognizing that there may be a much bigger opportunity nearby. When you reach this decision point, it can be beneficial to try a big experiment. You may also choose to take a step back and look for an opportunity that might be orthogonal to the original vision but could provide a significant improvement.
You notice in the graph that the investment never reaches zero. This gap reveals the secret, hidden, fifth step of the framework.
Maintain It
Even if there is no active development on a feature, it doesn’t mean that there isn’t any investment into it. The feature still takes up space in the product. It consumes valuable real estate in the UI. Its code makes adding other features harder. Library or system updates break it. Users find bugs. Writers have to maintain documentation about the functionality.
The investment cost means that it is critical not to add features to a product that do not demonstrably improve it. There is no such thing as a zero-cost feature. Suppose new functionality adds nothing to the product in terms of incremental value to users. In that case, the company must invest in maintaining it. Features that bring slight improvements to core metrics may not be worth preserving, given the additional complexity they add.
Expect failure all the time
When you talk about failure in the context of software development from the year 2000 to now, there is a substantial difference. Back then, you worked hard to write robust software, but the hardware was expected to be reasonably reliable. When there was a hardware failure, the software’s fault tolerance was of incidental importance. You didn’t want to cause errors yourself, but if the platform was unstable, there wasn’t much you were expected to do about it.
Today we live in a world with public clouds and mobile platforms where the environment is entirely beyond our control. AWS taught us a lot about how to handle failure in systems. This blog post from Netflix about their move to AWS was pivotal to the industry’s adapting to the new world.
Netflix’s approach to system design has been so beneficial to the industry. We assume that everything can be on fire all the time. You could write perfect software, and the scheduler is going to come and kill it on mobile. AWS will kill your process, and your service will be moved from one pod to another with no warning. We now write our software expecting failure to happen at any time.
We’ve learned that writing big systems makes handling failure complicated, so micro-service architectures have become more prevalent. Why? Because they are significantly more fault-tolerant, and when they fail, they fail small. Products like Amazon, Netflix, or Spotify all have large numbers of services running. A customer doesn’t notice if one or more instances of the services fail. When a service fails in those environments, the service is responsible for a small part of the experience; the other systems assume that it can fail. There are things like caching to compensate for a system disappearing.
Netflix has its famous chaos monkey testing, which randomly kills services or even entire availability zones. These tests make sure that their systems fail well.
Having an architecture composed of smaller services that are assumed to fail means that there is near zero user impact when there is a problem. Failing well is critical for these services and their user experience.
Smaller services also make it possible to use progressive rollout, feature flags, dark loading, blue-green deploys, and canary instances, making it easier to build in a fail-safe way.