I just saw a MS Surface commercial where someone used it comfortably on an airplane tray table. They must be in mega first class because I’ve seen people try to use them on “real” tray tables. It’s hilarious. The keyboard sticks out over the too-small space between your body and the tray table, and the backend comically and continuously falls off the other edge.
The kickstand was literally the stupidest thing on the first version of that product. It was fine if you wanted to watch a movie, but it wasn’t even at a good angle for that most of the time. With the Surface vertical you can’t type on it, although with its’ weird aspect ratio, you can’t comfortably type on it anyway. Since the device wasn’t really useful without the keyboard, essentially you ended up having a laptop without a hinge. That laptop hinge has survived for decades for a reason. The reason is that it works, and it works well.
Try and use a Surface on your lap. You can’t type on the screen, and you need to be nearly horizontal (or amazingly long limbed) to even fit it with the keyboard on your lap. Did Microsoft only test this on tables? Just bad, bad, bad design.
With the second version of the Surface, they kept the kickstand, but they are now marketing it as a device for doing work instead of entertainment. Now the design is even stupider. The kickstand on the surface2 seems to have two positions, which is a slight improvement, but it is still worthless without a keyboard, and it still won’t fit on a tray table or your lap.
I can’t believe they are doubling-down on this.
For the record, at one time I had TWO surface RTs. I had my company purchase one for me when they were first launched. I seriously tried to use it and gave up after a couple weeks of frustration. The second was given to me by Microsoft when I attended the Microsoft MIX conference. That one I never took out of the box and eventually gave it away since I knew I would never use it.
someone is faking my skype # for robocalls. So I get a dozen people *69ing every hour. Some leave angry voice mails.
I never used it anyway, so I just cancelled the skype number subscription, thinking that it would actually CANCEL MY SUBSCRIPTION. Except Microsoft won’t cancel it until the subscription runs out. IN NOVEMBER. MS customer support never replied to my messages.
Will probably need to create a new Skype account, which is lame.
Running a phone service is hard, running an IP Telephony service is harder. I expect the same level of support that I would get from a telephone service provider, but I also expect that I should have complete control and access, just like any web service. Unfortunately Skype is doing neither in this case.
[Update March 3rd, 2014]
I finally was forced to upgrade for work reasons to 11.1.4. I found a suggestion on the Apple forum and decided to try that.
These were my steps:
First I backed EVERYTHING up, my media drive and my iTunes library to a separate disk.
Then I quit iTunes, moved my iTunes folder out of my user directory so that it wouldn’t get picked up after I restarted.
I updated iTunes to 11.1.4.
Then I launched the app and let it create a new iTunes folder and library.
I made sure that all the sync settings were off, so that no apps or podcasts would be synced over iCloud.
I quit iTunes
I moved my iTunes folder back into my user directory.
I relaunched iTunes and let it update.
So far, this has worked ok (for about 4 weeks for me). I periodically do a check of my library to make sure that no files have been lost and it looks ok for now. I have seen posts on the Apple forum that points to people still having podcasts deleted days after upgrading, so I’m going to continue to check ofter.
I will likely do a similar process every time I update iTunes from now on. I will probably also avoid updating any version as long as I can. Unfortunately, I’ve lost all trust in that application that I have been dependent on for years.
I also want to mention that a friend with contacts on the iTunes team actually forwarded a link to this post and the forum thread as well to some folks in the team. The response (not official, just person-to-person, second hand) was that this wasn’t an issue they thought was affecting many users and therefore it wasn’t a major priority for the team. That may be true (as an engineering leader, I’ve made that decision myself a few times), but as a user it is creating massive problems for, it is of little comfort. This issue may have been fixed by the team anyway, possibly, but the recent comment from Ed, seems to point otherwise.
[Update October 5th – There is a new version of iTunes, 11.1.1, in the release notes it claims that it fixed an issue with deleted podcasts. I installed it. It ran fine for a while (it didn’t fix the podcasts it broke, but it didn’t screw any more up), and then it hung, spinning beach ball. I had to Force Quit it after a few minutes. When I relaunched, it had COMPLETELY REMOVED MOST OF MY PODCAST SUBSCRIPTIONS AND UNSUBSCRIBED ME FROM THE ONES THAT WERE LEFT. Luckily, I had backed up before this happened and I was able to copy over my iTunes folder and relaunch which restored all my podcast subscriptions, until it beach-balled again AND REMOVED THEM AGAIN (I didn’t force quit this time). I then checked my file folders and of course it DELETED MY FILES WITHOUT WARNING, AGAIN!!! DO NOT UPGRADE TO ITUNES 11.1 IF YOU SUBSCRIBE TO PODCASTS! At this point, I once again have to completely reconstruct my podcast library due to poor Apple engineering.]
[Update September 23rd – The Situation is even worse than I thought. iTunes 11.1 is basically useless for podcasts now, see below]
I have been using iTunes since version 1 or 2. I’m not sure. A very long time (nearly a decade). When they added podcast support, I switched from the podcatcher I was using to iTunes and have been using it ever since to sync my podcasts.
While I don’t save every episode from every podcast I have ever had, I do save some of them, which means I have literally years of archived podcasts. Or rather, I should say that I HAD years of archived podcasts. When I upgraded to iTunes 11.1, what I didn’t notice was that Apple somehow unsubscribed me to some of my podcasts or it got confused as to my subscription state. Interestingly, it was the ones that I actually tend to listen to pretty regularly. When it did this, IT SILENTLY DELETEDÂ big chunks of the episodes that had been downloaded from those casts.
This is a data-loss bug, the absolutely worst kind of bug imaginable. A stop-ship bug, a never-release-until-fixed issue. Unfortunately Apple did release it. I didn’t notice that this had happened, but at some point, I got a warning about how I was running out of space on my system drive, so I emptied the trash. I noticed that it seemed like I had a lot more files than I expected, but I didn’t think that much about it (I generally leave files in the trash until I need space). A day or so later, I noticed that iTunes didn’t think I was subscribed to a bunch of my podcasts, and that those podcasts were now missing dozens of archived episodes.
So now I will spend the next several days restoring from my on-line and off-site backups and slowly reconstructing my podcast library. Unfortunately, I now also need to worry about what other files may have been quietly cleaned up by iTunes: music, ebooks, movies? If there are more, I may never notice.
In the end, it means that a piece of software that I have used daily and depended on for years and years can no longer be trusted. The effect of this loss of trust cannot be understated. It would be the first step to me looking for another solution; one that wouldn’t have me locked into Apple’s platform. This is why this kind of bug is so amazingly critical to catch and why missing it is not a small issue, but a catastrophic one for an ISV or IHV.
If you are a long-time user of iTunes, beware 11.1, and everyone should have MULTIPLE backups of their files, for just this kind of event. I’m very glad that I have a complete backup of all my files on a hard drive that I can use to restore and an on-line additional backup in case that drive is busted.
[Update September 23rd]
After several hours of re-downloading episodes and restoring from backups, I relaunched iTunes only to find that it had deleted those episodes AGAIN. This means that this wasn’t an issue with upgrading the database, but rather a much more serious issue. This is beyond a critical issue for people who have large libraries of podcasts in iTunes. It seems that it doesn’t affect other parts of the library, but I’m not sure I can trust that for sure. This is a major issue since I have several iDevices and switching to another application is basically out of the question for the moment. I now have to work around this bug and hope that Apple will eventually fix it while being wary of the app deleting files every time it is launched. As a user, this sucks.
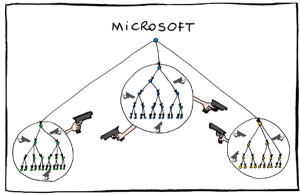
However, knowing that organization, I don’t know if there is much chance that it will be successful. The whole organization has been set up to compete with each other for decades. This kind of cultural change is probably beyond what is possible at this point. The battle lines are too well established, the rivalries too set in stone.
The culture of Microsoft has always been one of intense competition. Successful individuals and managers rise more on their ability to outshine their peers rather than cooperate. A new high-level alignment or a single memo will not change that. If Microsoft really wants to be nimble and more collaborative, they need to clear house.
Furthermore, organizing engineering as massive silos that are parallel to the other massive silos representing other business functions is exactly the wrong way to do this. Every new effort will require coordination between massive groups with conflicting priorities, politics and agendas. Everything will be harder. The company itself is so massive that having responsibility for the success meet at the tops of these tall functional mountains will not be sufficient to make these efforts work. The people with responsibility will be too far away from the details to be effective. Layers upon layers of management (each with their own goals, agendas and success metrics) will need to be navigated to get any level of cooperation.
It’s going to be a tough few years for the employees at the company. For the front-line engineers, their day-to-day work will probably not change much, but at the higher levels, there is going to be tremendous pain as the new structure and corresponding power battles work themselves out. In the end, I expect very little will change on the inside, or the outside.
The best part of this talk was getting a nice write-up on anandtech (one of my go-to sites). You can also find this talk synced to a recording of me speaking on NVidia’s site.
Amongst my many problems is the fact that I am a bit of a pack rat. Not bad enough to be on “hoarders” but bad enough that I have a hard time getting rid of stuff. My studio at home is cluttered with hundreds of books, CDs, DVDs, video tapes, papers and other assorted items I’ve accumulated over my life. Books are the toughest for me to part with. I’m always picking them up faster than I can finish them so the piles get larger and larger. Also books are the biggest shelf hogs off all the stuff I accumulate. Part of the problem is that even once I finish a book, I always assume that I’ll want it around to re-read or reference some day.
The answer is, of course, to stop buying new books until I make up some lost ground in my to read pile and just get over my fetishizing of
the books I’ve already read. Like any pack rat will tell you, that is pretty tough to do.
A more modern answer is to switch to buying e-books. This won’t fix my deepening pile of To-Read things (in fact it might make it worse because I won’t be able to see my physical pile of books to read), but it would address the clutter.
I love the concept of e-books. There are a lot of books that I buy that I won’t buy as e-books, like art monographs, but mostly I read non-fiction. For the majority of the books I read, the physical object really isn’t doing anything special for conveying the ideas. Most of the stuff I read would come across just fine on an electronic reader. To this end, I did get one a couple years ago. However, when I started to look into buying e-books, I was pretty disappointed.
I have a rule about DRM. I won’t buy any digital item with DRM. I’ve been burned several times over the years with vendors sunsetting their DRM schemes leaving their customers with a lot of bits they paid for but cannot access. DRM-free versions of e-books absolutely exist, but with such a high premium that they are often much more expensive than their physical counterparts. Even the DRM’d e-books are often as or more expensive than their physical versions, especially if they have already been out for a few years. So with the exception of a few O’Reilly titles, I basically haven’t purchased any e-books and have mostly just used my e-reader to read academic papers or other PDFs.
Last year, I purchased a Fujitsu ScanSnap scanner to help me address the piles of papers cluttering my desk, file cabinet and boxes in the garage. This was the answer to my pack-rat ways. It allowed me to have digital, searchable, copies of every piece of paper I ever wanted without having to actually keep the physical piece of paper. As I said, it also meant that I have a searchable archive, thanks to DRM. I’ve slowly been working my way through all my clutter, one file folder and one box at a time and it feels liberating. I’m finally clearing out magazines I’ve saved for 10 years to read one article and ridiculous crap like that. My recycle bin is always full.
Today, I finished reading Daniel Pink’s Drive. I read most of it a while ago, but it was sitting on my nightstand for a year or so while I read other books until I got around finishing it. I won’t review it here, other than to say that it was a pretty good book, but if you watch this video and understand the concept, you really have no need to buy it. This was a book that I thought was pretty good, but it didn’t say anything to me that I didn’t already know. What I should have immediately done was put it in a box to donate to a library, or given it to a friend, or a clueless boss, or something. Instead, I went to find a place for it on one of my overwhelmed shelves.
Then I spied my scanner.
I realized that this physical book didn’t have anything special about it. It came from a computer file, was printed on cheap paper and was actually the worst manifestation of the ideas from a standpoint of me being able to reference it again. If there was something I remembered from this book that I wanted to look up: I’d need to remember that it came from this book instead of from another one, then I’d need to remember where I put the book (home, work, a box in the garage), and then I’d need to actually find the section of the book that I was looking for. These days, I probably wouldn’t get past step one. I’d google for my answer and then never go to step two.
I decided to see how hard it would be to turn my physical book into an e-book for future reference. It was actually really easy. The whole process took less than twenty minutes.
First I got the tools… Tools of (Creative) DestructionI ended up not needing the smaller box cutter, the bigger one worked great.
Here we goI clamped the book to my desk. It is upside down because I’m right handed and I didn’t want to slice my fingers off. The ruler was only necessary for the first couple passes, but I kept using it as a finger guard. I put the ruler a bit in from the spine of the book and just got to work.
faster progress than I expectedI figured that it was going to take a really long time to slice through a whole book with an admittedly dull box cutter, but actually it took nearly no time at all.
almost doneThis was maybe 8 times through with the box cutter in a 260-some page book.
<Ready for scanningBefore I did this, I figured this was going to take me for ever. It probably took me more time to get all the tools together than it did for me to finish slicing off the spine.
The scansnap does its jobI just started feeding pages into the scanner. That went quick.
scanning...Man, I love the ScanSnap.
into the recycling binIt felt a bit weird, throwing a book into the recycling bin. I had a bit of a hard time with that. Part of me was ready to find a jumbo binder clip so I could still keep the book. That is really how my mind works.
in AcrobatI used Acrobat Pro’s OCR engine on the PDF generated by the ScanSnap. The original PDF was 26MB. After OCR, it was less than 11MB and more legible. The OCR went pretty quick. I guess this is about the best possible case for an OCR engine, so that shouldn’t be too surprising.
Live in iBooksAnd here is my new e-book on my virtual bookshelf.
reading in iBooksAnd here it is in the iBooks reader app.
The nice thing is that I could also read it on pretty much any e-reader, computer, or mobile device with a screen. That is the genius of open standards and DRM-free files. Even if some day the PDF format dies, I know that I’ll be able to take my book to whatever the next format or reading device is. Just like a real book.
I’m privileged to once again be speaking at the SC conference. For those who don’t know it; “SC is the International Conference for High Performance Computing, Networking, Storage and Analysis.” If you are attending, I’ll be on a panel entitled Parallelism, the Cloud, and the Tools of the Future for the next generation of practitioners. I’ll be joining some of my compatriots in the Educational Alliance for a Parallel Future to once again discuss the skill sets that collegiate computer science programs should (and mostly aren’t) imparting to their students in the areas of parallel programming.
The abstract for the panel is as follows:
Industry, academia and research communities face increasing workforce preparedness challenges in parallel (and distributed) computing, due to the onslaught of multi-/many-core and cloud computing platforms. What initiatives have begun to address those challenges? What changes to hardware platforms, languages and tools will be necessary? How will we train the next generation of engineers for ubiquitous parallel and distributed computing? Following on from the successful model used at SC10, the session will be highly interactive, combining aspects of BOF, workshop, and Panel discussions. An initial panel will lay out some of the core issues in this topic with experts from multiple areas in education and industry. Following this will be moderated breakouts, much like collective mini-BOFS, for further discussion and to gather ideas from participants about industry and research needs.
If this sounds similar to the session from the Intel Developer Forum in September, there is good reason. It was the second most popular session of that conference. The IDF panel and breakout sessions covered some really interesting ground, and I really liked the format. I felt like the discussions I had with the people in my subgroup at IDF were deeper, more specific and more productive than a traditional panel format would have been.
While the speakers in this panel are different than the one in September, I think we’ll still end up splitting on the axis of using abstractions to teach fundamentals vs teaching from the first principles up. Which camp you are in seems at least somewhat determined by the fact that a number of panelists produce abstractions over the low-level elements as part of their work. I am very much in the fundamentals camp as I think that understanding what the abstractions are built on is fundamental to choosing the right abstraction, much as artists tend to start with representative figure drawing. What will make an interesting difference from IDF is the number of audience members who come from outside of computer science (HPC is used more by scientists for whom the computation is only a means to the end of solving a problem in a non-computational discipline). Those audience members are less likely to understand the fundamentals, nor care. For them parallelism is just a tool to get their answer faster. This should really make for a lively debate!
My statement for the panel is as follows (yes, I did crib the last paragraph from my earlier position):
The team I manage is building a single, modern, software product. A few years ago, that would have meant a desktop application written primarily in C++, most likely single-threaded. Today, it means software that runs on the desktop, but also on mobile devices and in the cloud. Working in my organization are developers who write shaders for the GPU, developers who write SSE (both x86 and ARM), developers using distributed computing techniques on EC2 and threads everywhere throughout the clients and server code. We write code in C, C++, ObjC, assembly, Lua, Java, C#, Perl, Python, Ruby and GLSL. We leverage Grand Central Dispatch, pThreads, TBB and boost threads. How many of the technologies that we use today in professional software development existed when we went to school? Nearly none. How many will still be used in a few years from now? Who knows. The reason we can continue to work in the field is that our education was grounded not just in programming techniques for the technology of the time, but also in computer architecture, operating systems, and programming languages (high level, low level and domain-specific).
Learning GPGPU was much easier for me because I could understand the architecture of graphics processors. I was able to understand Java’s garbage collection because I understood how memory management worked in C. I chose TBB over Grand Central Dispatch to solve a specific threading problem because I could evaluate both technologies given my experience
with pThreads.
We’re doing students a disservice if we teach them the concepts using high-level abstractions or only teach them a single programming language. Having an understanding of computer architecture is also critical to a computer science education.
These fundamentals of computer science do not necessarily need to be broken out into their own classes. They can and should be integrated throughout the curriculum. Threading should be part of every course. It is a critical part of modern software development. Different courses should use different programming languages to give students exposure to different programming models.
If I was a Dean of Computer Science somewhere, I¹d look to creating a curriculum where parallel programming using higher-level abstractions was part of the introductory courses using something like C++11, OpenMP or TBB. Mid-level requirements would include some computer architecture instruction. Specifically, how computer architecture maps to the software that runs on top of it. This may also include some lower level instruction in things like pThreads, Race conditions, lock-free programming or even GPU or heterogenous programming techniques using OpenCL. In later courses focused more on software engineering, specific areas like graphics, or
larger projects: I¹d encourage the students to use whichever tools they found most appropriate to the tasks at hand. This might even include very high level proprietary abstractions like DirectCompute or C++AMP as long as the students could make the tradeoffs intelligently because of their understanding of the area from previous courses.
You can read the position statements from the rest of the panel here.
Getting this into your hands required a tremendous effort from a great team, and there is a lot more to come. More than just supporting more platforms like Android and Windows. This first version is just the tip of the iceberg. We wanted to put it into your hands, but it isn’t done. There is a lot more we want to do, but we want to hear from you. What do you need to make Adobe Carousel work even better for you? We want to know. We’re already hard at work on the next release, and hope to put it into your hands soon. Until then, download the client from the Mac App Store (requires Lion) or the iTunes app store. We have a 30 day free trial. Upload some photos, create a new Carousel to share with family or friends. Edit your photos and see how much Adobe imaging power we’ve been able to fit in your hands. The subscription pays for UNLIMITED storage for both you AND THE PEOPLE YOU SHARE WITH. That is a pretty serious deal.
Want to know more? This post on the Photoshop blog provides a lot of the official details and links.
This video summarizes what we are trying to create:
and this video tells you more about the team that I am so proud to be a part of (no actors, just really us):
Wondering why I sound so tired in that video? We shot it only days before we finished the product and we’d all been putting in long hours for weeks!
I’m posting this here because it took me more than 20 minutes of googling to find the answer (and I’m an Adobe employee).
The Adobe Connect uses Flash and sometimes if you do an update to Flash on your system, Connect gets into a bad state. The way you’ll see this is that when the Add-in tries to launch it will get stuck with a small window that says “Loading Adobe Connect…” that never finishes.
The way to fix this problem is to uninstall Adobe Connect. Unfortunately, Adobe doesn’t make it easy for you to do that. there is no uninstaller and no information on the Adobe web site. Here is where the add-in is installed
Delete that directory and you have now uninstalled the add-in. Your connect sessions will now be hosted in your web browser until the next time you need add-in functionality, at which time you’ll be prompted to re-install it.
Hopefully this solves your problem and you found it faster than I did.


 Destruction")




















